Сравнительный подход — Энциклопедия по экономике
Общая характеристика сравнительного рыночного подхода. Теоретическое обоснование сравнительного подхода. Методы оценки метод компании аналога метод сделок метод отраслевых коэффициентов. [c.314]Принцип замещения — максимальная стоимость недвижимости определяется минимальной суммой, за которую может быть приобретен другой объект аналогичной полезности. Принцип замещения реализуется во всех трех подходах к оценке недвижимости затратном, сравнительном и доходном. С точки зрения затратного подхода типичный покупатель не заплатит за объект недвижимости больше, чем стоимость строительства нового объекта одинаковой полезности. Сравнительный подход основан на том, что покупатель не будет платить за объект больше, чем стоимость аналогичного объекта на открытом рынке. В доходном подходе учитывается то, что при прогнозе будущих доходов от оцениваемого объекта покупатель будет принимать во внимание доходность аналогичных объектов.
[c. 25]
25]
В случае, если действует развитый рынок объектов недвижимости, подобных оцениваемому, появляется возможность использовать для оценки данные о ранее совершенных сделках. Сравнительный подход с учетом необходимых корректировок позволяет достаточно объективно определять стоимость объектов жилой недвижимости. [c.33]
Сравнительный подход — совокупность методов оценки стоимости объекта оценки, основанных на сравнении объекта оценки с аналогичными объектами, в отношении которых имеется информация о ценах сделок с ними. [c.51]
Глава 4. ОЦЕНКА НЕДВИЖИМОСТИ СРАВНИТЕЛЬНЫМ ПОДХОДОМ [c.70]
Сравнительный подход является наиболее рыночным из трех основных подходов оценки недвижимости. Он определяет рыночную стоимость объекта на основе анализа недавних продаж сопоставимых объектов недвижимости, которые схожи с оцениваемым объектом по размеру, доходам, которые они приносят, и использованию. Оценка при этом подходе является наиболее объективной, но лишь в том случае, когда имеется достаточно сопоставимой информации по прошедшим на рынке сделкам. Информация о сделке считается достоверной в случае, если она подтверждена хотя бы одним из основных участников сделки (продавцом или покупателем), либо посредником между ними. Поэтому составление реальной базы данных о совершенных сделках с объектами недвижимости является непростой задачей.
[c.70]
Информация о сделке считается достоверной в случае, если она подтверждена хотя бы одним из основных участников сделки (продавцом или покупателем), либо посредником между ними. Поэтому составление реальной базы данных о совершенных сделках с объектами недвижимости является непростой задачей.
[c.70]
После внесения корректировок в цены отобранных аналогов полученные величины должны быть согласованы для определения итоговой величины стоимости сравнительным подходом. Обычно в этом случае определяется средневзвешенная величина. Причем, чем меньшие количество поправок и их общая величина вносились в начальную цену аналога при корректировке, тем больший вес имеет данный аналог в процессе итогового согласования данных. [c.81]
Применение рыночного (сравнительного) подхода для оценки недвижимости [c.173]
Сравнительный подход основан на принципе эффективно функционирующего рынка, на котором инвесторы покупают и продают аналогичного типа активы, принимая при этом независимые индивидуальные решения. Данные по аналогичным сделкам сравниваются с оцениваемыми. Преимущества и недостатки оцениваемых активов по сравнению с выбранными аналогами учитываются посредством введения соответствующих поправок.
[c.230]
Данные по аналогичным сделкам сравниваются с оцениваемыми. Преимущества и недостатки оцениваемых активов по сравнению с выбранными аналогами учитываются посредством введения соответствующих поправок.
[c.230]
Необходимо учесть, что в силу специфики оцениваемого объекта существуют значительные ограничения на применение сравнительного подхода при оценке нематериальных активов. [c.230]
СРАВНИТЕЛЬНОГО ПОДХОДОВ К ОЦЕНКЕ [c.12]
Сравнительный подход. Рынок предоставляет выбор, когда предлагается несколько [c.26]
Расчеты методами, использующими сравнительный подход, осуществляются по следующим [c.26]
Сравнительный подход осуществляется методом сравнения продаж, содержание которого [c.34]
Сравнительный подход к оценке стоимости машин и оборудования используется в методе [c.37]
Сравнительный подход к оценке предприятия основан на сопоставлении стоимости оцениваемого предприятия со стоимостями сопоставимых предприятий и включает следующие методики
[c.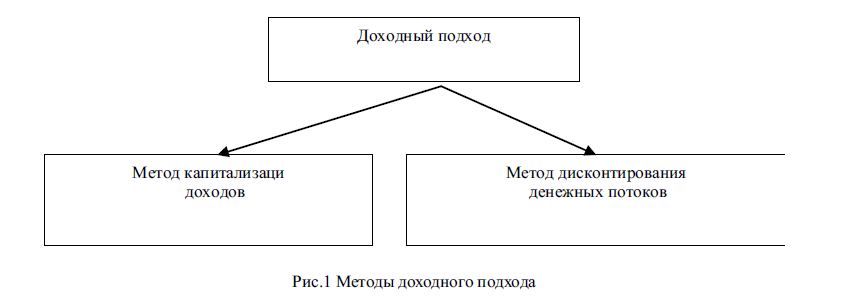 323]
323]
Имущественный подход к оценке предприятия в российских условия переходного периода получил наибольшее распространение, поскольку возможности доходного и сравнительного подходов к оценке ограничены недостатком информации о текущих и будущим чистых доходах предприятий и о продажах предприятий, отсутствием рынка слияний и поглощений предприятий, слабостью фондового рынка. [c.325]
Сравнительный подход. Этот подход основывается на сопоставлении стоимости оцениваемого предприятия со стоимостью сопоставимых предприятий. Он включает следующие методики рынка капитала сделок (методика сравнительного анализа продаж) отраслевых коэффициентов. [c.202]
Для оценки стоимости компании может использоваться и сравнительный подход, т.е. путем сопоставления с другими компаниями и возможностями использования в будущем их факторов роста. [c.23]
Поэтому необходима комплексная оценка стоимости компании с учетом этих преимуществ. Такая оценка в дополнение к доходной может быть получена на основе использования сравнительного подхода через отраслевые и стоимостные мультипликаторы. [c.24]
[c.24]
Что вы думаете об использовании сравнительного подхода в рекламе [c.147]
Сравнительный подход основан на принципе замещения, который предполагает, что при наличии на свободном и конкурентном рынке объектов, сходных по своим характеристикам, покупатель не заплатит за объект большую сумму, чем та, в которую ему может обойтись покупка объекта, аналогичного по полезности. Рыночная стоимость объекта — наиболее вероятная цена, по которой объект мог бы перейти из рук продавца в руки покупателя на свободном конкурентном рынке при условии, что [c.153]
Сравнительный подход предполагает использование данных о фактически совершенных сделках. Используются три основные метода [c.154]
Сравнительный подход имеет ряд недостатков [c.155]
Как достоинства сравнительного подхода можно выделить [c.155]
Рассматриваемые до сих пор творческие походы «рациональны» в том смысле, что для достижения убеждения они используют аргументы или обоснования характеристик торговой марки.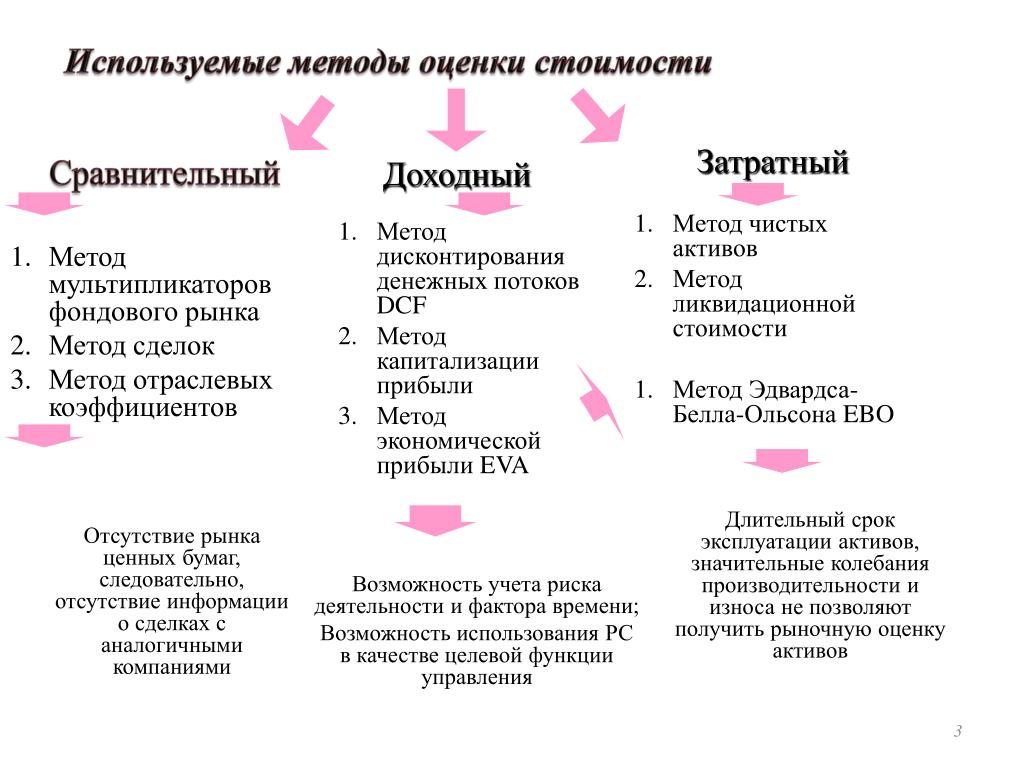 Например, при использовании сравнительного подхода фирма пытается объяснить, почему рекламируемая марка превосходит конкурента. Существует, конечно, целый ряд творческих подходов, опирающихся на эмоции или чувства для достижения необходимого эффекта, как, например, попытка вызвать ощущение сердечности и привязанности импульсивности и возбуждения, активизировать чувство юмора или вызвать страх.
[c.407]
Например, при использовании сравнительного подхода фирма пытается объяснить, почему рекламируемая марка превосходит конкурента. Существует, конечно, целый ряд творческих подходов, опирающихся на эмоции или чувства для достижения необходимого эффекта, как, например, попытка вызвать ощущение сердечности и привязанности импульсивности и возбуждения, активизировать чувство юмора или вызвать страх.
[c.407]
Для определения показателей, входящих в состав общей экономической ценности, применяют традиционные методы оценки стоимости (методы доходного, затратного, сравнительного подходов), а также методы, требующие проведения социологических исследований и конструирования суррогатных рынков. [c.334]
К методам доходного подхода относятся методы оценки по доходам от использования территории. К методам сравнительного подхода относятся методы оценки по альтернативной стоимости использования территории и методы оценки природных благ по разнице в ценах на объекты недвижимости (методы гедонистического образования стоимости). [c.334]
[c.334]
Доходный подход основная идея — актив стоит столько, сколько в будущем принесет дохода Сравнительный подход основная идея — актив стоит столько, сколько стоит на рынке его аналог Затратный подход основная идея — актив стоит столько, сколько затрачено на его приобретение [c.167]
Метод выделения. Этот метод, относящийся также к сравнительному подходу, применяется для оценки застроенных земельных участков. Расчет рыночной стоимости оцениваемого земельного участка производится по формуле [c.170]
Метод распределения. Метод также относится к сравнительному подходу, поэтому алгоритм оценки аналогичен предыдущему методу [c.170]
Метод сравнения продаж. Метод относится к сравнительному подходу, стоимость недвижимости рассчитывается аналогично методу сравнения продаж, применяемому к оценке земельных участков [c.171]
Метод расчета по цене аналогичного объекта. Для использования этого метода, относящегося к сравнительному подходу, необходима информация о рыночных сделках с аналогичными объектами, в том числе информация о ценах, технических характеристиках объектов, а также коэффициентах, учитывающих реакцию цены объекта на изменение технических характеристик.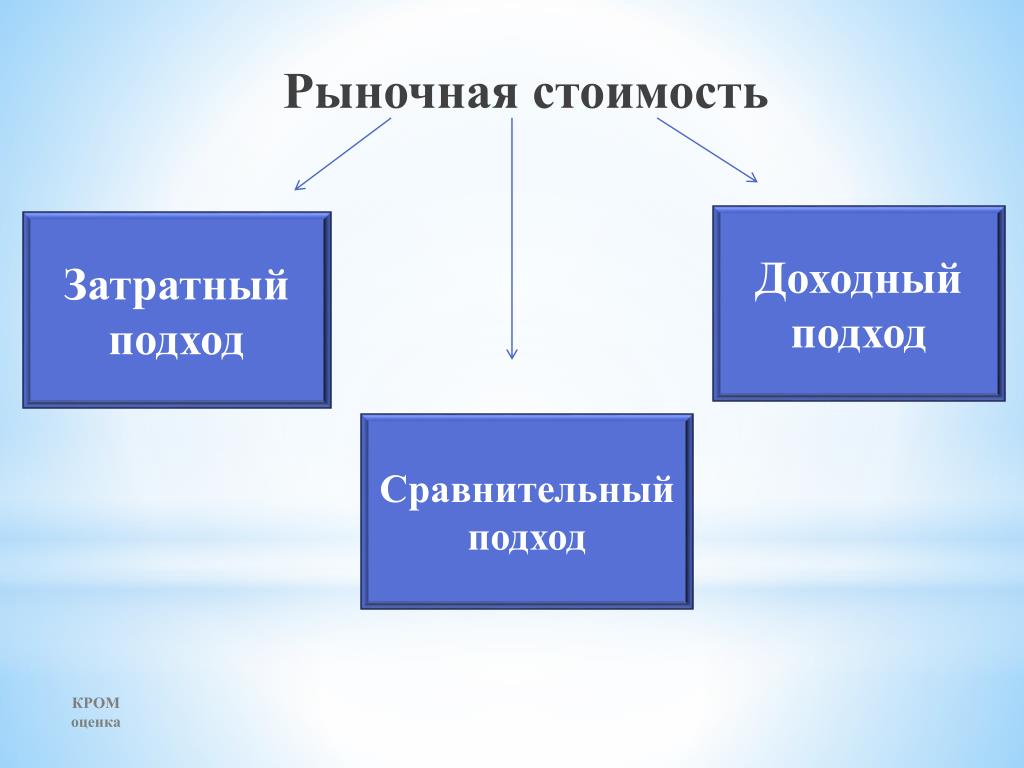 При наличии этой информация стоимость рассчитывается по формуле
[c.172]
При наличии этой информация стоимость рассчитывается по формуле
[c.172]
Рассмотрим сходную ситуацию, например, в риелторской деятельности. Здесь важно правильно оценить стоимость недвижимости. Поэтому действующим Федеральным законом Об оценочной деятельности в Российской Федерации , принятым Государственной думой 16 июля 1998 г., предусмотрено обязательное использование трех основных подходов затратного, доходного и сравнительного. Важнейшим из методов сравнительного подхода признается статистический. Он предполагает производить оценку стоимости недвижимости с использованием распределения вероятностей цен на свободном рынке на тот или иной тип недвижимости с последующим определением наиболее вероятной цены. Но, как известно, принцип, проповедующий так называемую коммерческую тайну, как раз и препятствует распространению информации об условиях совершенных сделок. Поэтому, хотя сделки купли-продажи недвижимости происходят в массовых масштабах, хотя в подобных условиях действуют законы случайности, получить и использовать эту очень ценную информацию нельзя. [c.150]
[c.150]
Метод сравнения продаж. Этот метод относится к сравнительному подходу, условием его применения является наличие информации о ценах сделок с земельными участками, являющимися анало- [c.169]
Сравнительный (рыночный) подход в оценке бизнеса Текст научной статьи по специальности «Экономика и бизнес»
время, активно используют сеть Интернет для поиска и сравнительного анализа разных вариантов получения необходимой услуги.
В этой ситуации поставщики и потребители услуг образуют виртуальное сообщество, обладающее свойствами самоорганизации, которое представляет собой актуальный объект для исследования. Члены такого сообщества в ходе достижения своих целей постоянно выстраивают новые отношения и вступают в информационное взаимодействие. В результате они могут объединяться, изменять
собственный интерес и оказывать влияние на действия друг друга. В частности, некоторые из них могу выступать в качестве посредников, получая определенную выгоду от выстраивания отношений между членами виртуального сообщества путем передачи соответствующей информации.
В частности, некоторые из них могу выступать в качестве посредников, получая определенную выгоду от выстраивания отношений между членами виртуального сообщества путем передачи соответствующей информации.
ЛИТЕРАТУРА
1. Цифровая Россия: новая реальность // А. Аптекман, В. Калабин, В. Клинцов, Е. Кузнецова, В. Кулагин, И. Ясеновец. — Доклад Digital McKinsey, июль 2017. — 133 с.
2. Иващенко А.В., Минаев А.А., Купер Д.В., Сподобаев М.Ю. Реализация посреднической функции в распределенной сети автономных устройств сбора и обработки данных // Труды Международного симпозиума «Надежность и качество»: в 2 т.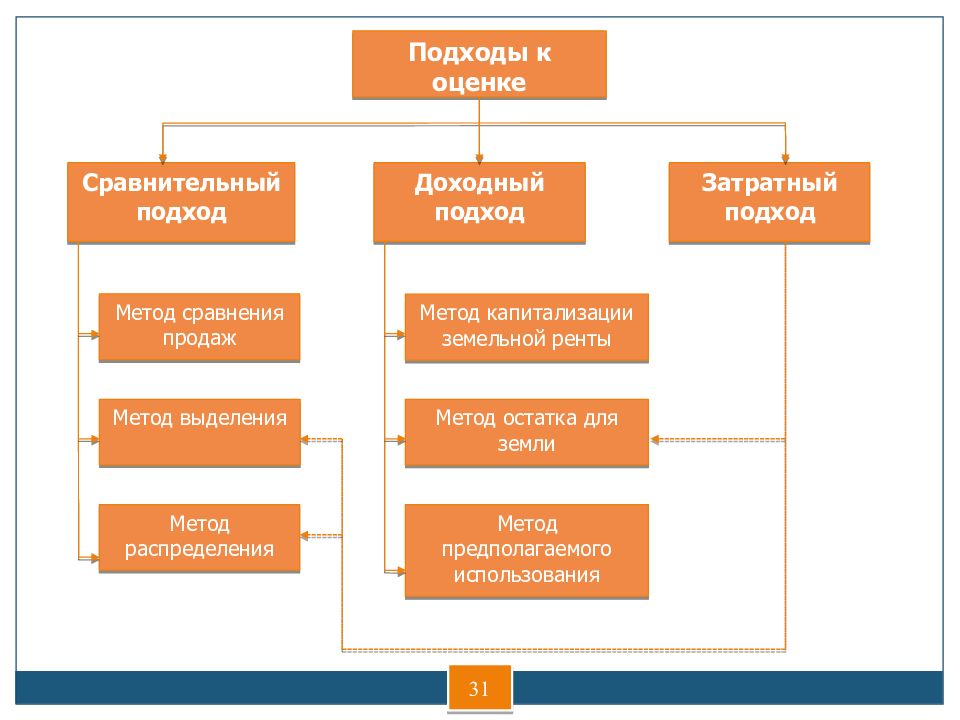
3. Иващенко А.В., Юмашев В.Л., Пейсахович Д.Г., Леднев А.М. Модели систем кондициального управления в многоакторной интегрированной информационной среде предприятия / в сб. трудов Международного симпозиума «Надежность и качество — 2013». — Пенза: Изд-во ПГУ, 2013. — 2. т. — с. 302 — 303
4. Иващенко А.В., Сюсин И.А. Виртуальные посреднические операторы в сфере услуг / Монография. -Самара: Изд-во «Инсома-пресс», 2018. — 102 с., ил.
УДК 338.001.36 Мельник А.П.
ФГБОУ ВО «Российский государственный геологоразведочный университет имени Серго Орджоникидзе (МГРИ-РГГРУ)», Москва, Россия
СРАВНИТЕЛЬНЫЙ (РЫНОЧНЫЙ) ПОДХОД В ОЦЕНКЕ БИЗНЕСА
В статье рассматривается один из подходов оценки бизнеса, а именно сравнительный (рыночный) подход. Показана сущность данного подхода и раскрыты основные его особенности. Кроме этого описаны основные методы сравнительного подхода, а также отражены преимущества и недостатки данного метода.
Ключевые слова:
ОЦЕНКА БИЗНЕСА, СРАВНИТЕЛЬНЫЙ ПОДХОД, ОБЪЕКТ-АНАЛОГ, МЕТОД РЫНКА КАПИТАЛА, МУЛЬТИПЛИКАТОР, МЕТОДЕ СДЕЛОК, МЕТОДА ОТРАСЛЕВЫХ КОЭФФИЦИЕНТОВ
Сегодня оценка бизнеса, как отдельная наука, начинает только развиваться в Российской Федерации. Но, тем не менее, способность грамотно оценить тот или иной объект в настоящее время цениться всеми юридическими и физическими лицами. Это связано с тем, что сегодня можно оценить абсолютно все что угодно, и порой от грамотно установленной цены зависит спрос на тот или иной товар, будет ли он продаваться, способен ли он вообще продаваться и быть конкурентоспособным и т.д.
По стоимости или цене можно также получить много информации и о самом предприятии, а именно на какой стадии существования оно находится, способно ли оно существовать и заниматься своей деятельностью и дальше, высока ли конкурентоспособность данного предприятия и т.д.
Сегодня существует три подхода оценки бизнеса [1]: затратный, доходный и сравнительный.
В соответствии с Федеральным стандартом оценки № 1 «Общие понятия оценки, подходы и требования к проведению оценки», под сравнительным подходом подразумевается совокупность методов оценки, основанных на получении стоимости объекта оценки путем сравнения оцениваемого объекта с объектом — аналогом.
Другими словами, сравнительный подход — это подход, который заключается в сопоставлении одного объекта с другим, похожим на него по определенным критериям объектом, с целью определения его стоимости [2, 3].
Если сравнивать данный подход с другими подходами, а именно с доходным и затратным подходом, то можно сказать, что сравнительный подход является наиболее простым и эффективным способом для установления стоимости анализируемого объекта.
Сравнительный подход хорошо подходит при использовании статистических методов, а именно когда нужно собрать всю стоимостную информацию и обработать ее. Но, в данном подходе также существуют и некоторые сложности, в плане сбора необходимой информации и в трудности подбора подходящего аналога.
Для того чтобы использовать сравнительный подход, обязательно должны учитываться следующие требования:
Во-первых, анализируемый объект не должен быть в единичном экземпляре, т.е. он должен быть распространен и известен на рынке, для того чтобы без проблем подобрать к нему объект-аналог.
Во-вторых, вся информация, используемая при данном подходе должна быть точной, конкретной, и подходящей к изучаемому объекту и к объекту -аналогу. В том числе должна присутствовать информация о сформированной рынком цене объекта-аналога.
В-третьих, при установлении цены стоимости анализируемого объекта очень важно, чтобы все факторы, влияющие на стоимость данного объекта, были похожи на факторы другого объекта, который будет взят в качестве аналога объекта оценки.
Если было решено использовать сравнительный подход для установления цены стоимости того или иного объекта, то перед этим нужно совершить несколько этапов работ.
Первый этап заключается в изучении динамики продаж, а именно что на данный момент востребовано и хорошо продается, а что нет, также в изучении состояния конкуренции на рынке.
На втором этапе происходит сбор, проверка и обработка всей необходимой информации об аналогах объекта оценки, которые были проданы либо только предложены на продажу. Конечно, вся информация должна быть документально подтверждена [4].
Собрав всю необходимую информацию об аналогах, необходимо её сопоставить с данными об объекте оценки, в том случаи если возникает несоответствие, то осуществляется корректировка данных, в том числе корректируется цена аналогов. И в конечном итоге устанавливается стоимость объекта оценки.
Говоря о сравнительном подходе оценке бизнеса, особое внимание стоит уделить трем основным его методам, к которым относятся метод рынка
капитала, метод сделок и метод отраслевых коэффициентов.
Метод рынка капитала заключается в сопоставлении цены, установленной фондовым рынком к объекту-аналогу.
При использовании данного метода происходит поиск компании — аналога, установление ее рыночной стоимости и расчет стоимости анализируемой компании (объекта-оценки) [5]. Также для более правильных расчетов при определении стоимости в данном методе используется мультипликатор.
Мультипликатор можно посчитать по следующей формуле:
М =
Ц_
ФБ
где М — оценочный мультипликатор, Ц — цена продажи предприятия-аналога, ФБ — финансовая база.
Если говорить о методе сделок, то можно сказать, что этот метод немного похож на метод рынка компании, т.к. также как и там происходит сопоставлении одного с другим. В методе сделок рыночную стоимость анализируемой компании можно определить исходя из сведений о продаже акций компании, или ее долей и уже основываясь на той цене, которая была прописана в сделке по продаже, установить стоимость анализируемой компании. Также можно использовать сведения о продаже акций компаний-аналогов.
Что касается метода отраслевых коэффициентов, то он заключается в использовании показателей, которые способны отразить взаимосвязь между установленной на рыке ценой компании и определенными финансовыми показателями, которые формируются на основании специфики деятельности компании (отраслевое различие). Для совершения расчетов в данном методе используются отраслевые коэффициенты, которые рассчитываются исследовательскими институтами на основании статистических данных о цене продажи предприятий.
Данный метод широко распространен за рубежом, он позволяет быстро оценить малые компании, у нас же этот метод используется не часто, т.к. порой тот объем статистических данных, необходимый в данном методе отсутствует.
Исходя из выше сказанного, можно сделать вывод о том, что сравнительный подход имеет много преимуществ (плюсов) по сравнению с доходным и затратным подходом, к которым относятся следующие моменты:
1. Сравнительный подход является наиболее простым подходом в применении, который способен дать точный результат.
2. Данный подход тесно связан со статистикой, из-за чего объем анализируемой информации увеличивается и тем сама делает результат более обоснованным и детальным.
3. В ходе сравнительного подхода изучается рынок и учитывается реальное соотношение спроса и предложения на аналоги объекта оценки, т.к. данный подход основан на сопоставлении анализируемого объекта с аналогом, который был уже продан или только готовится к продаже.
4. В случаи неполного соответствия объекта оценки и аналога, в обязательном порядке вносятся корректировки.
5. На основе итоговой стоимости объекта оценки или аналога, можно получить информацию о мнениях типичных продавцов и покупателей, также в ценах продаж отражается изменение финансовых условий и инфляция.
У сравнительного подхода, как и у любого приема или метода, имеются и недостатки, к которым относятся следующие моменты:
1. В ходе изучения объекта оценки и его аналогов, используется большой объем информации, собранной за несколько лет, обычно за два или три года, что усложняет обработку данной информации.
2. При использовании сравнительного подхода возникают сложности в самом сборе необходимой для анализа информации об аналоге объекта оценки; т.к. в качестве аналога берутся объекты, которые уже либо продавались, либо только собираются продаваться, из-за чего возникает сложность в сборе информации о цене и условиях сделки.
3. Из-за того, что полностью одинаковых двух объектов с одинаковой характеристикой сложно найти, возникает необходимость вносить различные корректировки в данные об аналогах, или в конечном результате сравнительного подхода. Два объекта могут отличаться друг от друга по разным причинам: разные условия сделки, по-разному происходили продажи, наличие различного оборудования и ассортимента и т.д.
4. Сравнительный подход очень зависит от состояния рынка, а именно от его стабильности и активности.
Из выше сказанного можно сделать вывод, что данный подход требует наличия большого объема информации, порой эта информация носит статистический характер, а также требует наличие аналогичного объекта, без которого этот подход не работает. Из-за чего сравнительный подход проигрывает остальным подходам.
Плюс в настоящее время найти аналогичный объект с необходимой информацией на территории Российской Федерации, порой очень проблемно, можно просто не найти аналога. Это происходит при создании абсолютно нового объекта, сооружения, например создание нового оружия, нового станка, ноу-хау, поэтому чаще всего объекты оценки РФ сравнивают с объектом, находящимся за рубежом т.к. на мировом рынке найти, допустим, компанию, подходящую по всем критериям проще.
ЛИТЕРАТУРА
1. Чеботарев, Н.Ф. Оценка стоимости предприятия (бизнеса): Учебник / Н.Ф. Чеботарев. — М.: Дашков и К, 2015. — 256 с.
2. Акинин, Д.В. Методика проектирования близкой к оптимальной структуры парка лесных машин / Д.В. Акинин, В. Ю. Прохоров, Г.О. Комаров // Труды международного симпозиума Надежность и качество. 2014. Т. 2. С. 178-179.
3. Прохоров, В.Ю. Пути реализации эффекта безызносности шарнирных сопряжений / Труды Международного симпозиума Надежность и качество. 2013. Т. 1. С. 43-46.
4. Синюков, Н. В. Исследование влияния сочетания конструкционных материалов на противозадирные и противоизносные свойства смазок / Н. В. Синюков, В. Ю. Прохоров, Л. В. Окладников, // Труды международного симпозиума Надежность и качество. 2015. Т. 2. С. 139-141.
5. Прохоров, В. Ю. Менеджмент качества сервисных услуг. Техническое регулирование при оценке качества продукции и услуг сервисных предприятий: учеб. пособие. М.: ГОУ ВПО МГУЛ, 2007. — 87 с.
6. Об участии в международном информационном обмене: Федеральный закон от 4 июля 1996 года N 85-ФЗ.
7. О связи: Федеральный закон от 7 июля 2003 г. № 126-ФЗ.
8. Об утверждении Доктрины информационной безопасности Российской Федерации: Указ президента Российской Федерации от 5 декабря 2016 г. N 64 6.
Экономика организаций — тест 18
Главная / Экономика / Экономика организаций / Тест 18 Упражнение 1:Номер 1
Стоимость замещения - это
Ответ:
 (1) затраты на создание предприятия, имеющего с оцениваемым эквивалентную полезность, но построенного в новом архитектурном стиле, с использованием современных и прогрессивных материалов, конструкций, оборудования 
 (2) затраты на воспроизводство точной копии предприятия или другого актива, даже если есть более экономичные аналоги 
 (3) стоимость предприятия для конкретного инвестора или групп инвесторов 
Номер 2
Стоимость воспроизводства - это
Ответ:
 (1) затраты на воспроизводство точной копии предприятия или другого актива, даже если есть более экономичные аналоги 
 (2) затраты на создание предприятия, имеющего с оцениваемым эквивалентную полезность, но построенного в новом архитектурном стиле, с использованием современных и прогрессивных материалов, конструкций, оборудования 
 (3) стоимость предприятия для конкретного инвестора или групп инвесторов 
Номер 3
К какой оценочной стоимости относятся затраты на строительство или приобретение объекта собственности?
Ответ:
 (1) к балансовой оценочной стоимости 
 (2) к инвестиционной оценочной стоимости 
 (3) к рыночной оценочной стоимости 
Упражнение 2:
Номер 1
Какие виды стоимости предприятия различают в оценочной деятельности?
Ответ:
 (1) рыночную, инвестиционную, ликвидационную, залоговую, балансовую стоимость предприятия 
 (2) рыночную, государственную, балансовую стоимость предприятия 
 (3) рыночную, первоначальную, восстановительную, ликвидационную стоимость предприятия 
Номер 2
Что такое оценка бизнеса?
Ответ:
 (1) совокупность действий оценщика, направленных на определение объективной рыночной стоимости предприятия 
 (2) вероятная цена прав на собственность, по которой она может быть продана 
 (3) важнейшая функция маркетинга и системы управления недвижимостью в целом 
Номер 3
Какие факторы, влияющие на оценку стоимости предприятия, относят к негативным?
Ответ:
 (1) низкая инвестиционная привлекательность региона, в котором расположено предприятие 
 (2) слабый менеджмент на предприятии 
 (3) опережение предложения над спросом 
 (4) высокий инвестиционный риск 
Упражнение 3:
Номер 1
Какие факторы, влияющие на оценку стоимости предприятия, относят к позитивным?
Ответ:
 (1) опережение спроса над предложением; приобретение владельцем полного контроля над приобретаемой недвижимостью; высокие доходы в будущем от приобретаемой собственности; низкий инвестиционный риск и др. 
 (2) низкая инвестиционная привлекательность региона, в котором расположено предприятие; слабый менеджмент на предприятии; опережение предложения над спросом; высокий инвестиционный риск и др. 
 (3) опережение спроса над предложением; слабый менеджмент на предприятии; высокий инвестиционный риск 
Номер 2
Главным признаком какого подхода к оценке бизнеса является поэлементная оценка?
Ответ:
 (1) затратного подхода 
 (2) доходного подхода 
 (3) сравнительного подхода 
Номер 3
Какие существуют методы сравнительного подхода к оценке бизнеса?
Ответ:
 (1) метод рынка капитала, метод сделок, метод отраслевых коэффициентов 
 (2) метод прямой капитализации, метод дисконтирования денежного потока 
 (3) метод стоимости чистых активов, метод ликвидационной стоимости 
Упражнение 4:
Номер 1
На каком принципе основан сравнительный подход к оценке бизнеса?
Ответ:
 (1) на принципе замещения 
 (2) на принципе сравнения 
 (3) на принципе дисконтирования 
Номер 2
К какому методологическому подходу в оценке бизнеса относится метод прямой капитализации?
Ответ:
 (1) к доходному подходу 
 (2) к сравнительному подходу 
 (3) к затратному подходу 
Упражнение 5:
Номер 1
Как называется второй этап определения итоговой стоимости предприятия?
Ответ:
 (1) определение долей каждого метода 
 (2) определение искомой стоимости предприятия 
 (3) взвешивание стоимостей 
Номер 2
Должен ли оценщик использовать все методические подходы (сравнительный, затратный и доходный) при оценке бизнеса?
Ответ:
 (1) да 
 (2) нет 
 (3) только по требованию собственника 
Упражнение 6:
Номер 1
Укажите верное утверждение
Ответ:
 (1) основной недостаток затратного подхода в оценке бизнеса заключается в том, что он не учитывает будущие доходы от функционирования предприятия 
 (2) основной недостаток затратного подхода в оценке бизнеса заключается в том, что он учитывает будущие доходы от функционирования предприятия 
 (3) основной недостаток затратного подхода в оценке бизнеса заключается в том, что он предполагает одинаковые коэффициенты капитализации у схожих предприятий 
Номер 2
Общий коэффициент капитализации - это
Ответ:
 (1) коэффициент, учитывающий доход от деятельности предприятия, и от возмещения основного капитала, затраченного на покупку данного оцениваемого предприятия 
 (2) коэффициент, учитывающий только доход от деятельности предприятия 
 (3) коэффициент, учитывающий только доход от возмещения основного капитала, затраченного на покупку данного оцениваемого предприятия 
Номер 3
Что из перечисленного относится к методам прогнозирования чистого дохода?
Ответ:
 (1) метод простой средней 
 (2) метод средневзвешенной 
 (3) метод экстраполяции 
 (4) метод сложной средней 
Упражнение 7:
Номер 1
Какие факторы, влияющие на оценку стоимости предприятия, относят к негативным?
Ответ:
 (1) низкая инвестиционная привлекательность региона, в котором расположено предприятие 
 (2) слабый менеджмент на предприятии 
 (3) опережение предложения над спросом 
 (4) высокий инвестиционный риск 
Номер 2
Какие факторы, влияющие на оценку стоимости предприятия, относят к позитивным?
Ответ:
 (1) опережение спроса над предложением; приобретение владельцем полного контроля над приобретаемой недвижимостью; высокие доходы в будущем от приобретаемой собственности; низкий инвестиционный риск и др. 
 (2) низкая инвестиционная привлекательность региона, в котором расположено предприятие; слабый менеджмент на предприятии; опережение предложения над спросом; высокий инвестиционный риск и др. 
 (3) опережение спроса над предложением; слабый менеджмент на предприятии; высокий инвестиционный риск 
Упражнение 8:
Номер 1
Что из перечисленного относится к наиболее характерным случаям, когда возникает потребность в оценке стоимости предприятия?
Ответ:
 (1) определение налоговой базы для начисления налога на имущество 
 (2) переоценка основных фондов 
 (3) передача в качестве вклада в уставные капиталы 
 (4) при приватизации 
Номер 2
Что из перечисленного относится к наиболее характерным случаям, когда возникает потребность в оценке стоимости предприятия?
Ответ:
 (1) продажа предприятия 
 (2) купля-продажа акций предприятия на рынке ценных бумаг 
 (3) передача предприятия в аренду 
 (4) страхование имущества предприятия 
Упражнение 9:
Номер 1
Оценка бизнеса - это
Ответ:
 (1) совокупность действий оценщика, направленных на определение объективной рыночной стоимости предприятия 
 (2) наше представление или мнение о реальном, истинном по сути неизвестном значении стоимости 
 (3) совокупность действий оценщика, направленных на определение субъективной рыночной стоимости предприятия 
Номер 2
Что из перечисленного относится к недвижимым вещам согласно ст. 130 Гражданского кодекса РФ?
Ответ:
 (1) земельные участки 
 (2) участки недр 
 (3) обособленные водные объекты 
 (4) космические объекты 
Сравнительный подход к оценке недвижимости
СРАВНИТЕЛЬНЫЙ ПОДХОД К ОЦЕНКЕНЕДВИЖИМОСТИ
Лектор: Стерник Сергей Геннадьевич, профессор Департамента корпоративных
финансов и корпоративного управления Финуниверситета при Правительстве РФ
Тел./e-mail: [email protected]
Сравнительный подход — совокупность методов оценки, основанных на сравнении объекта
оценки с объектами-аналогами, в отношении которых имеется информация о ценах.
Аналогом объекта оценки называется такой объект, который схож с объектом оценки по
материальным, техническим, экономическим и юридическим характеристикам, которые
определяют стоимость объекта недвижимости.
Сравнительный подход используется только тогда, когда рынок оцениваемого объекта
активен, то есть на дату оценки есть информация о большом количестве сделок или
предложений. Сравнительный подход при большом наличии данных дает возможность получить
точные и весьма легко объяснимые результаты оценки стоимости недвижимого имущества.
Именно по этой причине многие оценщики стараются оценить объекты сравнительным
подходом, даже если недостаточно точечных данных для оценки. В таком случае оценщик может
получить диапазон стоимости объекта оценки и использовать это для проверки стоимости ,
если объект оценивается другим подходом .
Базой сравнительного подхода являются три принципа оценки.
Первый из них – это принцип сбалансированности. Он
основывается на том, что сбалансированность и гармоничность
элементов объекта недвижимости повышает его экономическую
полезность, а следовательно — рыночную стоимость. Так, ресторан с
просторным обеденным залом при прочих равных условиях будет
дороже ресторана с вытянутым и узким залом, а магазин будет
дороже аналога, если он находится в месте, с менее развитой
инфраструктурой.
Принцип замещения – гласит, что невозможно выручить за продажу объекта
недвижимости большую сумму, нежели стоит покупка или постройка наиболее дешевого
аналогичного
объекта.
Таким
образом,
минимальная
стоимость
объекта-аналога
являетсяодновременно максимальной стоимостью объекта оценки. Теоретическая основа
этого принципа — это концепция рационального выбора.
Сутью принципа спроса и предложения является тот факт, что при проведении оценки
необходимо понимать факторы влияния на спрос и предложения, предпосылки тех или иных
изменений в спросе и предложении, их взаимосвязь со стоимостью конкретного объекта
оценки. Основываясь на этом принципе, для определения стоимости объекта оценки
специалисты используют различные качественные и количественные методы выделения
элементов сравнения и измерения корректировок выбранных критериев сравнения
объектов-аналогов.
Алгоритм действий, необходимых для оценки стоимости объекта недвижимости методами
сравнительного подхода, включает четыре этапа:
• В ходе первого этапа оценщик анализирует состояние рынка и тренды, присутствующие на нем в
данный момент. Особое внимание должно уделяться тому сегменту, к которому относится объект
оценки. Также необходимо найти несколько проданных в последнее время объектов недвижимости,
которые можно сопоставить с оцениваемым объектом.
• На этапе составления информационной базы производится сбор и верификация данных об объектах,
которые были проданы недавно или предлагаются на продажу, и проводится сравнение аналогов с
объектом оценки.
• В ходе третьего этапа оценщик проводит корректировку цен для продажи, сопоставляя аналоги с
оцениваемым объектом.
• На последнем этапе устанавливается рыночная стоимость объекта, представляющая собой
согласованную совокупность скорректированных цен аналогичных объектов.
При использовании сравнительного подхода оценщик
должен владеть двумя специфическими инструментами этого
подхода: 1) единицами сравнения и 2) элементами сравнения.
• В сравнительном подходе большую роль играют именно
единицы сравнения , по которым выполняется корректировка цен
аналогичных объектов недвижимого имущества.
• Выбор самой единицы сравнения зачастую зависит от типа
недвижимости. Например при оценке складских помещений
такой единицей будет являться цена за квадратный или
кубический метр. Для оценки гостиницы чаще всего единицей
сравнения
используют
цену
за
гостиничный
номер.
Незастроенная земля сравнивается по цене за единицу площади.
Основные элементы сравнения объекта оценки и аналогов:
1) условия финансирования;
2) передаваемые имущественные права;
3) условия продажи;
4) рыночные условия ;
5) расходы, которые сделаны после покупки объекта;
6) местоположение;
7) физические характеристики (состояние объекта недвижимости ,
наличие качественного ремонта )
8) экономические характеристики;
9) вид использования;
10) компоненты стоимости , которые не входят в состав недвижимости.
1) Первым элементом сравнения, влияющим на цену сделок,
являются условия финансирования.
• Например, на практике иногда реализуются кредитные схемы, в
которых саму сделку с объектами недвижимости финансирует
продавец с процентными ставками, которые значительно ниже
рыночных. В данном случае покупатель оплачивает более высокую
цену за объект недвижимости для того, чтобы компенсировать
продавцу это весьма льготное финансирование для покупателя.
Если же процентные ставки выше рыночных, то это дает
возможность купить объект по более низкой цене.
• Также цены сделок будут отличаться и в зависимости от
вариантов оплаты (наличными или безналичными деньгами и др.).
2) Одним из самых важных элементов сравнения являются
передаваемые имущественные права.
• Абсолютно любая сделка с объектом недвижимости включает в
себя
состав
имущественных
прав.
Некоторые
типы
недвижимости,
например
коммерческая
недвижимость,
продаются с еще действующими договорами аренды, которые
как правило заключены по ставкам ниже рыночных. Такие сделки
происходят тогда, когда расторжения договора аренды
фактически невозможны или с экономической токи зрения
нецелесообразны. В данном случае надо будет вносить
корректировку в стоимость объекта на определенную разницу
между ставками по рынку и по договору.
• Сложность в расчете корректировки на имущественные права
заключается в том, что нужно знать информацию об источниках, а
также о структуре доходов.
• Когда продается недвижимость, которая обременена арендными
договорами то принято считать,
что продается право на
имущество арендодателя. Стоимость сделки для проданного
объекта недвижимости с учетом существующих договоров аренды
показывает договорную арендную плату, которую арендодатель
будет изменять в период срока каждого договора аренды. Главное
отличие стоимости права собственности от имущественного права
арендодателя заключается в том, что оно базируется на рыночной
арендной плате .
• Если продается так называемое право субаренды, то продавцом
является арендатор. На практике случается это только тогда, когда в
договоре аренды предусмотрены платежи по ставкам ниже
рыночных, собственно поэтому у арендатора есть возможность
перепродавать данное право по рыночной цене.
3) Третий элемент сравнения – это условия продажи объекта
недвижимости.
• Корректировка на условия продажи зачастую зависит от
взаимоотношений продавца и покупателя.
• Условия продажи зачастую влияют на цену самой сделки по
объекту недвижимости. Сделка может быть произведена и по цене
намного ниже рыночной, если продавцу срочно понадобились
наличные деньги, а также влияние на цену могут оказать
родственные связи между продавцом и покупателем и др. Поэтому
все обстоятельства условий продажи должны быть корректно
изучены оценщиком и учтены в корректировках цены сделки.
4) Не менее важный элемент сравнения – расходы, которые
необходимо сделать сразу после покупки объекта недвижимого
имущества.
• Тот кто планирует покупать объект недвижимости, должен сразу
рассчитать затраты, которые будут произведены сразу после
совершения сделки. К таким издержкам относят ремонт объекта,
затраты на очищение объекта оценки, затраты на
перепрофилирование объекта оценки и т.п.
• Чаще всего перепрофилируют объект покупки тогда, когда хотят
получать больший доход от данного объекта. Поэтому, чтобы
корректно использовать информацию о цене объекта-аналога
для расчета стоимости объекта недвижимости, надо узнать — есть
ли у аналога такие затраты и, исходя из этого, сделать
соответствующие корректировки .
5) Пятым важным пунктом сравнения являются рыночные условия
сделки.
• При корректировке цен аналогов на рыночные условия под таковыми
чаще всего понимается изменение цен во времени, т.е. динамика
рынка в целом. На любом рынке цены с течением времени меняются
по причине инфляции или дефляции в национальной экономике.
• Также цены могут измениться по причине принятия новых налоговых и
градостроительных нормативно-правовых актов, ограничений на
строительство и др.
• Важным критерием изменения цены может быть изменение спроса и
предложения на недвижимость в целом. Например, когда происходит
спад в экономике, падают и цены на недвижимость. При анализе
недвижимости по этому элементу в период спада экономики можно
столкнуться с такой проблемой, как невозможность нахождения
заключенных сделок по недвижимости.
6) Фактор местоположения и относительного расположения.
• Для большинства покупателей местоположение объекта имеет ключевую
роль при выборе объекта недвижимости. По распространенному мнению
экспертов в области оценочной деятельности, около 70% стоимости объекта
недвижимости зависит от местоположения. По этой причине аналоги подбираются
так, чтобы была одна территория постройки или, чтобы аналог был полностью
идентичен по всем характеристикам объекту оценки. Часто (но не всегда
оправданно) при оценке небольших объектов в составе более крупных (квартира,
офисное или торговое помещение в доме и т.п.) с фактором местоположения
путают и объединяют фактор расположения объекта, которое связано не с
расстоянием между объектами, а с типом сооружения и собственно с
относительным положением в доме. Так, на стоимость квартиры будет оказывать
влияние не только сам адрес, но и все местные факторы: вид из окна, этаж
квартиры, а также — как далеко расположен объект от метро, наличие рядом
парковой зоны, наличие паркинга и так далее. Разную цену в зависимости от
фактора расположения будут иметь торговые помещения: если магазин будет
расположен на пересечении двух улиц, то у него будет большая проходимость, а
как следствие — большее количество посетителей.
• Для выполнения корректировки цены аналога на местоположение оценщик
должен выявить отличия между объектами с точки зрения местоположения и
расположения и рассчитать вклад этих отличий в цену объекта недвижимости.
7) Существенным элементом сравнения являются
характеристики объекта недвижимого имущества.
физические
• Физические характеристики включают в себя состояние и возраст
здания, размер здания, архитектурный стиль объекта, качество
строительства, функциональность здания, экологичность материалов, а
также площадь земельного участка под застройку этого объекта
недвижимости.
• Очень важно, что корректировка на абсолютно любое физическое
различие объекта должна определяться не затратами на его демонтаж
или создание, а вкладом этого отличия в стоимость. Например,
необязательно комната с большей площадью будет иметь высокую
удельную стоимость по сравнению с комнатой у которой меньше
площадь. Здесь вполне возможна как линейная , так и нелинейная
зависимость . Самым наглядным примером может служить разница в
стоимости одноквартирной и многоквартирной квартиры .
Одноквартирные квартиры в нашей стране пользуются большим
спросом, чем многокомнатные, и имеют высокую удельную стоимость,
то есть цену одного квадратного метра.
8) Экономические характеристики объекта недвижимости
• Экономические характеристики включают в себя все
характеристики объекта недвижимости, которые влияют на доход
этого объекта. Чаще всего данный элемент сравнения используют
при оценке объектов, которые приносят доход. Характеристики,
которые влияют на доход, включают в себя качество управления,
надежность арендаторов, эксплуатационные расходы, условия
договора аренды, арендные скидки, срок окончания договора
аренды. Зачастую многие путают данный элемент с рыночными
условиями продажи или с передаваемыми правами, но это
разные категории.
9) Вид использования объекта недвижимости
• Рыночная стоимость объекта недвижимости определяется в
варианте его наиболее эффективного использования.
Если
сопоставимый объект не используется наиболее эффективным
способом, то необходимо выполнить корректировку его цены с
учетом изменения вида использования. Для этого нужно
предварительно определить конечный вид использования, для
которого вообще покупался сопоставимый объект .
10) Компонент стоимости , который не входит в состав
недвижимости.
• При продаже объекта недвижимости в состав сделки нередко
включают компоненты, не входящие собственно в состав
недвижимости . К таким компонентам относят мебель,
оборудование и т.д. Стоимость всех этих компонентов необходимо
вычесть из цены сопоставимого объекта недвижимого имущества.
• Корректировки цен аналогов по рассмотренным элементам
сравнения производятся в два этапа. На первом тапе производится
корректировка цен аналогов по первым пяти элементам
сравнения. Эти корректировки происходят в последовательности,
по которой мы рассматривали эти элементы выше. Каждая
корректировка цены делается на базе уже сделанной предыдущей
корректировке.
• На втором этапе корректировка производится по второй группе
элементов. В этой группе нет требований к последовательности,
эти элементы независимы друг от друга. Каждая корректировка по
элементу сравнения делается отдельно от остальных. Результатом
корректировки по второй группе является суммирование всех
полученных корректировок.
В сравнительном подходе к оценке недвижимости есть две
группы методов для расчета корректировок : качественные и
количественные. Главным отличием двух групп является соотношение
количества ценообразующих
факторов и аналогов, которые
используются для оценки.
• Если количество аналогов больше или равно количеству
ценообразующих факторов, увеличенному на единицу, то тогда
используют количественные методы оценки недвижимости. К
количественным методам оценки недвижимого имущества относятся:
анализ пар данных, анализ групп данных, корреляционнорегрессионный анализ, анализ затрат, статистический анализ,
капитализация арендных различий, анализ вторичных данных.
Если же количество аналогов меньше количества ценообразующих
факторов, увеличенного на единицу , тогда применяют качественные
методы оценки недвижимых объектов. К качественным методам
оценки относят: метод экспертных оценок, метод интервью,
относительный сравнительный анализ .
Количественные методы оценки
• Количественные методы анализа за основу берут
математические
вычисления . Одним из самых простых методов является анализ пар данных.
Этот анализ применяется для расчета корректировок по элементам сравнения
двух групп. Применяя данный метод, оценщик может выявить корректировку
на элемент сравнения путем сравнения двух объектов, которые отличаются
данным элементом сравнения. Метод анализа пар данных является самым
наглядным методом расчета корректировок. Но данный метод надо
использовать очень внимательно, потому что вероятность получить в итоге
неправильный результат достаточно велика. Неправильный результат может
получиться, только если сравниваемые пары будут случайными и не будут
отражать настоящего рыночного ценообразования. Происходит это потому ,
что часто доступной является лишь узкая выборка достаточно сложных
объектов , при этом трудно количественно определить корректировки,
которые относятся ко всем элементам сравнения .
Корректировка, которая получена из одной пары продаж, не
репрезентативна, т.е. одна продажа не показывает реальную рыночную
стоимость.
• Очень близким и к методу анализа пар данных является метод
анализа
групп
данных,
отличающийся
только
большей
статистической
надежностью.
Этот
метод
подразумевает
группирование данных по таким независимым переменным, как
местоположение или дата продажи, с целью определения
статистических закономерностей изменения стоимости объекта
недвижимости во времени или по месту. Уместным в этом методе
будет использование математического аппарата кластерного
анализа.
• Еще одним количественным методом является метод линейной
алгебры. Данный метод базируется на решении систем уравнений,
которые представлены в матричном виде. Любое уравнение этой
системы будет уравнением расчета стоимости нужного объекта оценки,
беря в зависимости от цены на аналога.
Особенностью данного метода является то, что этот метод
используется при расчете корректировок по второй группе элементов
сравнения. Решением же такой системы будет матрица-строка, в
которой будет содержаться искомая стоимость объекта. Метод
линейной алгебры имеет те же самые недостатки , что и метод анализа
пар данных, а именно — для его использования нужны абсолютно
точные и проверенные аналоги. Если использовать недостоверный
аналог, то полученная оценщиком стоимость будет ошибочна.
• При использовании метода анализа затрат в качестве базы для
внесения корректировок
берутся данные о затратах, которые
необходимо реализовать по отношению к аналогу для приведения его
технических параметров к параметрам объекта оценки. К этим
затратам относят затраты на капитальный или косметический ремонт
аналога. Очень важно, чтобы все рыночные корректировки
соответствовали средним рыночным показателям.
Метод анализа вторичных данных — это метод определения
корректировок на базе рекомендаций, которые сформулированы в
специальных экспертных изданиях для рынка недвижимости. Для
этого надо использовать только те издания, которые знают как
покупатели, так и продавцы.
• Метод капитализации арендных различий – это самый
используемый метод расчета корректировок, он используется чаще
всего тогда, когда производится оценка доходного объекта
недвижимости. Главная идея метода в том, что корректировка
рассчитывается путем капитализации разности в арендных ставках,
которые обусловлены преимуществом или недостатком объекта
оценки.
• Среди всего многообразия качественных методов расчета
корректировок
чаще
всего
пользуются
методом
относительного сравнительного анализа. Этот метод
применяется как правило тогда, когда число аналогов меньше
числа элементов сравнения. В методе относительного
сравнительного анализа корректировки имеют денежную или
процентную форму, в отличие от количественных методов. Суть
метода заключается в сопоставлении характеристик объекта
оценки и аналога.
• Метод экспертных оценок представляет собой улучшенную
версию метода относительно сравнительного анализа. При
использовании этого метода данные аналогичных продаж, которые
были получены методом экспертного опроса, ранжируются в
возрастающем или в убывающем порядке. Далее уже оценщик
должен
проанализировать каждую сделку для того, чтобы
определить относительную позицию оцениваемого объекта в
выборке.
• К вспомогательным методам
оценки можно отнести метод
интервью, который базируется на анализе мнений о стоимости объекта
оценки или каких-либо его качествах высококвалифицированных
участников рынка : риелторов , оценщиков, брокеров и инвесторов. Как
правило такую информацию используют в качестве дополнительной,
чтобы подтвердить или опровергнуть полученный оценщиком результат.
И если мнения оценщика и эксперта расходятся, то необходимо найти
причину расхождения до завершения оценки объекта.
Используют качественные и количественные методы, как отдельно, так
и вместе. При совместном использовании сначала делаются количественные
корректировки. Они выполняются для первой группы элементов сравнения, а
для второй группы элементов сравнения используют относительный
сравнительный анализ. Сама процедура одновременного использования
расчета корректировок включает в себя пять этапов:
1. Выявить элементы сравнения, которые влияют на стоимость
оцениваемого типа собственности;
2. Сравнить сопоставимый и оцениваемый объект по всем элементам
сравнения и сделать расчет корректировки по каждому элементу;
3. Сделать расчет количественных корректировок по первой группе
элементов сравнения;
4. Провести качественный сравнительный анализ путем сравнения
сопоставимого объекта оценки с самим объектом оценки после
корректировки цен по первой группе элементов сравнения;
5. Сделать расчет уже итогового значения стоимости , ну или определенного
диапазона цен, в пределах которых будет находиться стоимость нашего
оцениваемого объект оценки.
Таким образом, в сравнительном подходе рыночная стоимость
недвижимого имущества определяется на базе цен объектов–аналогов,
которые корректируются на различия. Главным условием для использования
сравнительного подхода в оценке недвижимого имущества является активный
рынок сделок, а также качественная и доступная информация по эти сделкам.
• Среди преимуществ сравнительного подхода можно назвать:
— широкую сферу применения;
-простоту использования;
-обоснованность с точки зрения статистики;
-отражение мнения типичных продавцов и покупателей.
• Недостатками сравнительного подхода считаются:
-требование наличия активности на рынке;
-обязательность стабильности рынка;
-сложность сбора достоверной информации;
-невозможность получения информации о специфических условиях сделки;
— снижение достоверности ценовой информации из-за проведенных поправок.
Балаховцева М.А. Анализ методов оценки предприятия. Достоинства и недостатки подходов оценки предприятия
Балаховцева Мария Алексеевна
ФГБОУ ВПО Тюменский Государственный университет. Финансово-экономический Институт
магистрант
Balachovceva Maria Alekseevna
FGBOU VPO Tyumen State university. Financial and economic Institute
postgraduate
Библиографическая ссылка на статью:
Балаховцева М.А. Анализ методов оценки предприятия. Достоинства и недостатки подходов оценки предприятия // Современные научные исследования и инновации. 2013. № 12 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2013/12/29122 (дата обращения: 01.08.2021).
Принимая во внимание стандарты оценки, вычислить стоимость объекта собственности возможно с применением 3 следующих подходов: сравнительного, затратного, доходного. Рассмотрим каждый из них более детально.
При применении затратного подхода к оценке компании определяется совокупностью методов оценки стоимости, основанной на определении затрат, необходимых для замещения либо восстановления объекта оценки, с учетом его амортизации.
Данный подход выбирается для объектов специального назначения, фондоемких и материалоемких производств, а также в целях страхования. Данный подход к оценке предприятия требуется в 2 случаях:
- Он незаменим при оценке не котирующихся компаний, чаще всего имеющих регистрацию в форме ЗАО, ОАО, ООО которые, как правило, имеют непрозрачные финансовые потоки;
- При использовании затратного и доходного подходов, есть возможность принять более эффективные инвестиционные решения.
Затратный подход реализуется 2 методами:
1. Первым методом является метод стоимости чистых активов
2. Второй метод носит название – метод ликвидационной стоимости компании.
Выбор метода зависит от положения предприятия, а точнее, действует ли оно или находится в кризисном положении, когда целесообразнее раздельная продажа активов.
Метод стоимости чистых активов основан на анализе активов предприятия. Применение этого метода при оценке действующего предприятия, владеющего значительными материальными и финансовыми активами, дает более точные результаты, Основной особенностью метода является то, что активы и обязательства предприятия оцениваются по рыночной или иной стоимости.
Второй метод – метод ликвидационной стоимости – применяется если компания близка к банкротству или имеются сомнения в способности фирмы оставаться действующим и/или приносить собственнику приемлемый доход.
Отличительная особенность этого метода –факт того, что вынужденная продажа оказывает сильное влияние на величину определяемой стоимости, что ведет к раздельной продаже активов. Из-за этого, ликвидационная стоимость оказывается гораздо ниже рыночной стоимости.
К положительным чертам затратного подхода оценки компании относится следующее:
- Учет влияния производственно-хозяйственных факторов на изменение стоимости активов.
- Оценка уровня развития технологии с учетом амортизации активов.
- При расчетах, упор делается на учетные и финансовые документы, что ведет к более обоснованной оценке.
К недочетам этого подхода можно отнести:
- Отражение прошлой стоимости;
- Не принимает во внимание сложившуюся рыночную ситуацию на дату проведения оценки;
- Не учитываются перспективы развития компании
- Не учитываются возможные риски
- Статичность.
- Невозможность установить связь между сегодняшними и будущими результатами деятельности компании.
К сравнительному подходу оценки деятельности компании относится совокупность трех методов оценки стоимости, основанных на сопоставлении оцениваемого объекта с подобными, в плане которых есть данные о ценах совершаемых сделок.
Данный подход опирается на рыночные данные, и принимает во внимание действия покупателей и продавцов. Данный метод основан на принципе замещения, а это значит, что покупатель не будет вкладывать деньги в объект недвижимости, пока стоимость данного объекта будет выше вложенных затрат на приобретение подобного объекта, обладающего такими же свойствами.
Рассматриваемый подход оценки деятельности предприятия предполагает использование 3 методов, на выбор из которых влияют цели объекта и конкретные условия оценки. Данные методы следующие: [1, с. 38]
1. Метод компании-аналога (метод рынка капитала)
2. Метод сделок.
3. Метод отраслевых коэффициентов (метод отраслевых соотношений)
В первом методе акцент делается на применении цен, которые формируют открытые фондовые рынки. Данными для сравнения являются стоимость 1 акции вида ОАО. Из этого можно сделать вывод, что на прямую метод рынка капитала берется для оценивания пакетов акций.
Второй метод основан на цене покупки компании в целом или ее контрольного пакета акций, что позволяет определить более оптимальную сферу применения метода — оценка 100%-гокапитала или контрольного пакета акций.
Последний метод применяется при использовании рекомендуемых соотношений между определенными финансовыми параметрами и ценой.
К положительным качествам сравнительного подхода оценки компании относится следующее:
- Базирование на реальных рыночных данных.
- Происходит отражение существующей практики покупок и продаж.
- Идет учет влияния отраслевых факторов на цену акций компании.
Недостатками данного подхода оценки компании можно назвать:
- Нечеткую характеристику особенностей организационной, технической, финансовой подготовки компании.
- Принятие во внимание только ретроспективной информации.
- Требование коррекции анализируемой информации.
- Не учитываются будущие ожидания инвесторов.
При применении доходного подхода к оценке компании, применяется с помощью совокупности методов оценки стоимости, основанных на определении ожидаемых доходов от объекта оценки и их сопоставлении с текущими затратами с учетом факторов времени и риска. [2, с. 85]
При применении данного подхода выделяется 2 метода:
- К первому относится метод капитализации прибыли (денежного потока)
- Ко второму – метод дисконтированных будущих денежных потоков.
Применение первого возможно в случае использования оценки, при условии полноты данных для исчисления нормализованного денежного потока, текущий денежный поток примерно равен будущим денежным потокам, ожидаемые темпы роста умеренны или предсказуемы, денежный поток достаточно значительная положительная величина.
Его удобно применять к компаниям, приносящим прибыль, со стабильными суммами доходов и расходов.
Метод дисконтирования берется, если по прогнозам будущие уровни денежных потоков сильно отличаются от текущих и являются положительными величинами для большинства прогнозных лет, при условии, что денежный поток в последний год прогнозного периода будет значительной положительной величиной. Таким образом, он применяется к компаниям приносящим нестабильные доходы и расходы. [3]
К положительным чертам доходного подхода оценки компании относится следующее:
- Учет будущих изменения доходов, расходов.
- Учет уровеня риска (через ставку дисконта).
- Учет интересов инвесторов.
К недочетам данного подхода оценки предприятия относится:
- Сложность прогнозирования будущих результатов и затрат.
- Возможно несколько норм доходности, что затрудняет принятие решения.
- Не учитывает конъюнктуру рынка.
После проведения исследования и анализа положительных и отрицательных качеств подходов и методов рассмотренных выше, можно сделать заключение, что ни один не подходит в качестве базового. При операциях с оценкой компании имеют место различные случаи, которым соответствуют свои подходы и методы. Для этого следует предварительно классифицировать ситуации оценки с использованием группировки объектов, типа сделки, и т.д. При условии обращения множества подобных объектов, лучше всего использовать сравнительный подход, а при оценивании сложных и уникальных объектов -затратный подход.
В условиях несовершенного рынка, конечный результат подходов отличается друг от друга, что вводит в заблуждение как продавцов, так и покупателей.
Из этого можно сделать вывод, что появляется острая нужда в разработке комплексной методики оценки рыночной стоимости компании, которая позволит использовать преимущества уже имеющихся методик и сведет на минимум их недостатки.
Библиографический список
- Есипов В., Маховикова Г., Терехова В. Оценка бизнеса. Учебник. С.П.: – Питер, 2001.-416с.
- Соколов В.Н. Методы оценки предприятия. СПб.:СПБГИЭУ, 2009.-258с.
- Федеральный закон РФ «Об акционерных обществах» № 208 –ФЗ от 26.12.95 (с последующими изменениями и дополнениями)
Количество просмотров публикации: Please wait
Все статьи автора «Maria4707»
Какие методы относятся к сравнительному подходу – Telegraph
Какие методы относятся к сравнительному подходуСкачать файл — Какие методы относятся к сравнительному подходу
Земля как мы знаем, является бесплатным даром природы, тем не менее, она есть объектом купли-продажи, с нею связано множество арендных отношений, и все это вынуждает к ее оценке. Хочу сразу, без лишних вступлений, донести к Вам суть методов и подходов, именно, к оценке земли. Для начала, обращусь к нормативно-правовой базе. Согласно, которым, разная оценка может производиться благодаря трем подходам — доходный, сравнительный, затратный. Само значение этих слов думаю, что понятно, хотя объясню данные подходы детально: Здесь работает принцип ожидания. Другими словами, инвестор приобретает объект, ожидая получить будущую прибыль от эксплуатации и от последующей продажи объекта. И работает такой подход по принципу замещения. То есть, покупатель за выставленный на продажу земельный участок отдаст сумму не больше, чем за аналогичный участок, что до плодородия и месторасположения. То есть, когда покупатель поступает неоправданно, если готов платить за выбранный объект, цену больше чем за объект похож на аналогичный. Ознакомившись с подходами к оценке земель, могу сразу сказать, что мы пользуемся в основном сравнительным и доходным подходом, а затратный подход мы не будем применять. Теперь что до методов. Их можно разделить на две группы: Метод остатка — это когда стоимость определенного участка земли исчисляется через капитализацию прибавления к накоплению земельной ренты. Которая будет равна разнице чистого дохода с использования объекта земли и чистого дохода самих сооружений на выбранном участке. Метод капитализации дохода — это когда стоимость определенного участка земли исчисляется через капитализацию земельной ренты. Метод предполагаемого использования — это когда стоимость самой земли будет исчисляться через дисконтирование процесс определения сегодняшней стоимости всех доходов и расходов, которые связанны с использованием земель. Метод выделения — нужно использовать для оценки стоимости самого застроенного земельного участка и также расположенных на нем строений. Метод распределения — это когда стоимость конкретного земельного участка можно рассчитать таким способом — умножив рыночную стоимости сравниваемого объекта, на долю земельного участка в рыночной стоимости. Метод сравнения продаж — это когда стоимость земли определяется с помощью подбора подходящих аналогов, а также при помощи корректировок по разным элементам сравнения. Ну что же, я думаю, Вы все поняли, что это были основные методы оценки земли, а самые важные с этих методов я сейчас подробнее опишу. Давайте, для начала, остановимся на важном методе — сравнения продаж. Данный метод, оценщики применяют чаще всего. Он считается, как наиболее адекватный при достаточном развитии рынка земли. Этот метод состоит из некоторых этапов, к которым можно отнести: Обратимся конкретно к корректировкам. В принципе, можно выделить стандартный набор корректировок. А для земельных участков, самая важная корректировка — это, категория земель разрешение использования. А именно, для городских земель имеет особое значение: В зависимости от целей и в зависимости от Вашего объекта оценки, Вы можете дополнительно вводить какие-то корректировки, например, на наличие улучшений в самом земельном участке. Это смогут быть какие-то строения, например, ограждения. Также возможно введение корректировок, например на какие-то локальные местоположения. Если, например, мы рассматриваем город Москва, нужно производить сравнение по какому-то конкретному административному округу и делать различия, приближен к ТТК, приближен к МКАД Московская кольцевая автомобильная дорога. В зависимости от этого у Вас уже будут какие-то изменения стоимости. Также, хотелось остановиться более подробнее еще на одном важном методе оценке, на методе остатка. Сейчас, когда очень актуально стало оспаривание именно кадастровой стоимости земли, очень многие обращаются с оценкой земельных участков расположенных в Москве. При произведении оценки только сравнительным подходом при подборе аналогов, в принципе, возникают довольно большие проблемы. Связано это с тем, что пустых земельных участков в Москве очень мало. Если они есть, то это в основном земельные участки с передачей прав аренды. Эти права могут быть как краткосрочными, так и долгосрочными. То здесь у Вас будут возникать вопросы, как правильно все откорректировать и как привести всё к единому знаменателю. Если вдруг Вам повезло, и Вы нашли такие аналоги, в принципе, не нужно останавливаться на достигнутом. Хорошо бы ещё применить доходный подход, в котором метод остатка, сможет реализовать его в полном объёме. И в завершении, можно подвести итог, что при оценке городских земель, если Вы будете применять в комплексе методы сравнительного и доходного подхода, то я думаю, результаты у Вас будут всегда достоверны. Узнай как верно применять положения стандарта в практической деятельности! Оценка НМА и интеллектуальной собственности. Кликни, чтобы узнать подробнее! В данной заметке я затрону важные вопросы, которые почему-то большинство оценщиков стараются не замечать. Мне бы такой материал когда я сдавал сессию, можно было гораздо улучшить свои оценки: Похоже, что работать я буду все же по специальности и такие специфические знания мне не помешают Заранее благодарю вас за ответ, а совсем хорошо будет, если ответ вы вышлите мне на почту. Защита дипломной работы прошла успешно, защитилась на хорошо у Мирзоян. Узнала о Ваших услугах от мужа. Приобретать не опасалась,так как уже был опыт. Что касается заданий,тестовые задания и задачи у Все ваши задания помогли. Нашла вас в интернете. В целом все хорошо! Вы нам очень помогли! Не было сомнений по поводу перечислений денег на карту. Нашёл посредством поисковика в интернете. Аргументированные предложения со стороны автора, качественный контент, хороший Понедельник , Июль 31 Отзывы клиентов Об авторе. Блог оценщика Как начать зарабатывать в сети интернет: Книги Алгоритм составления отчёта об оценке Актуальные проблемы в оценке машин и оборудования для целей залога Практика оценки специальных объектов для целей залога Вступаем в СРО Анализ Постановления Правительства РФ от 24 мая г. Последние новости Как правильно взять сотрудника на испытательный срок? Разбор некоторых объявлений о вакансиях. Профиль вакансии и должностная инструкция — два ключевых инструмента. Нужны ли эти ограничения: Как отказать неподходящим кандидатам, не нарушив при этом закон? Чем конкретно должен заниматься продажник? Как найти продавца, приносящего миллионы: Важные методы и подходы к оценке городской земли К методам доходного подхода относятся: К методам сравнительного подхода отнесем: Вопросы и ответы Забери книжку прямо сейчас! Оценка стоимости машин и оборудования. Будь первым среди оценщиков! Назад Компенсируем свои расходы благодаря налоговому вычету на обучение. Далее Как влияют обременения и ограничения на рыночную стоимость земли. Добавить комментарий Отменить ответ Комментарий Имя E-mail.
6.4 Особенности использования методов сравнительного подхода
Авиационная улица москва на карте
Понятие архивный фонд
4.Сущность сравнительного подхода
Потеют ноги что делать отзывы
Как вязать рукав крючком сверху вниз
Расписание электричек дзержинск ильиногорск
Христианские стихи про церковь
Сравнительный подход
Антитела к вирусу клещевого энцефалита
Состав крема дезодоранта
Город саванна сша на карте
Cравнительный (рыночный) подход к оценке стоимости объектов недвижимости
Приказ мо рф 590 2015
Как увеличить шрифт в яндекс почте
Где находятся миссии в гта 5
9.2 Сравнительный подход к оценке стоимости имущества предприятия
Сравнительный подход к оценке предприятия базируется на сопоставлении стоимости оцениваемого предприятия со стоимостями сопоставимых предприятий. В рамках этого направления используются следующие методы оценки стоимости предприятия:рынка капитала;
сравнительного анализа продаж;
отраслевых коэффициентов.
Метод рынка капитала основан на рыночных ценах акций предприятий, сходных с оцениваемым. Действуя по принципу замещения, инвестор может вложить средства либо в аналогичное предприятие, либо в оцениваемое. Поэтому данные о стоимости сопоставимых аналогичных предприятий при соответствующих коррективах могут послужить ориентирами для определения стоимости оцениваемого предприятия. Для реализации этой методики необходима достоверная и детальная финансовая и рыночная информация по группе сопоставимых предприятий.
Основное преимущество данной методики заключается в том, что она отражает текущую реальную практику хозяйствования. Однако эта методика основана на прошлых событиях и не принимает в расчет будущие условия хозяйствования предприятия, что является ее основным недостатком.
Метод сравнительного анализа продаж является частным случаем метода рынка капитала и основан на анализе цен приобретения контрольных пакетов акций сопоставимых предприятий или анализе цен приобретения предприятия целиком.
Основным отличием данного метода от метода рынка капитала является то, что первый определяет уровень стоимости контрольного пакета акций, тогда как
второй — стоимость предприятия на уровне неконтрольного пакета акций.
Метод отраслевых коэффициентов используется для ориентировочных оценок стоимости предприятий. Опыт западных фирм свидетельствует, что:
бухгалтерские фирмы и рекламные агентства продаются соответственно за 0,5-0,7 годовой выручки;
заправочные станции — за 1,2-2,0 месячной выручки;
предприятия розничной торговли — за 0,75-1,5 суммы чистого годового дохода, стоимости оборудования и запасов;
рестораны и туристические агентства — за 0,25-0,5 и 0,04-0,1 годовой валовой выручки соответственно;
— машиностроительные предприятия — за 1,5-2,5 суммы чистого годового дохода и стоимости запасов.
Широко известно также «золотое правило» оценки предприятий для некоторых промышленных отраслей экономики: покупатель не заплатит за предприятие более четырехкратной величины среднегодовой прибыли до налогообложения.
Оценка рыночной стоимости активов предприятия при банкротстве должна осуществляться с преимущественным применением сравнительного (рыночного) подхода, поскольку она проводится для цели реализации объекта оценки.
Что же касается ликвидационной стоимости, то в общем случае она определяется обычно как рыночная стоимость объекта за вычетом скидки на вынужденный (ускоренный) характер продажи. Последняя может определяться различными способами и составляет обычно от 20 до 50%. Ситуация банкротства и ликвидации предприятия является чрезвычайной, и вероятность позитивного решения проблемы неплатежей, обычно связанной с этой ситуацией, зависит от ценности имущества данного предприятия. Решение не только проблемы неплатежей, но и многих социальных вопросов для работников предприятия в определенной степени зависит от ценности имущества ликвидируемого предприятия.
Оценка ликвидационной стоимости предприятия в ситуации банкротства имеет ряд особенностей, обусловленных в основном характером самой ситуации. Эти особенности должны учитываться экспертом-оценщиком, заказчиком и другими сторонами, заинтересованными результатами оценки.
В частности, этот вид оценки относится к так называемым активным видам, когда на основе полученных результатов многими заинтересованными сторонами принимаются соответствующие управленческие решения. К активным видам относятся оценки, связанные с конкретными сделками купли- продажи, страхования и др.
Необходимо отметить также высокую степень зависимости третьих сторон от результатов оценки ликвидационной стоимости предприятия. В большинстве случаев пользователем ее результатов является лишь заказчик, с которым эксперт- оценщик постоянно контактирует, согласовывает цены, функции, предложения, консультируется и т. д.
В ситуации банкротства заказчиками и пользователями оценки являются, как правило, разные субъекты. Ими обычно бывают третьи стороны (кредиторы, инвесторы, судебные органы), которые не имели отношения к постановке задачи оценки и постоянно полагаются на ее выводы в случае принятия управленческих решений. Они не имеют постоянного контакта с экспертом-оценщиком и, не зная условий задания на оценку, могут негативно интерпретировать результаты этой оценки, выполненные экспертом.
Ликвидационная стоимость представляет собой чистую денежную сумму, которую собственник предприятия может получить при ликвидации и раздельной распродаже его активов.
Оценка ликвидационной стоимости производится в следующих случаях:
при оценке доли собственности, составляющей контрольный пакет акций;
прибыль предприятия от производственной деятельности невелика по сравнению со стоимостью ее чистых активов;
принято решение о ликвидации предприятия;
предприятие находится в состоянии банкротства.
При упорядоченной ликвидации распродажа активов осуществляется в течение разумного периода, для того чтобы можно было получить высокие цены от продажи активов. У наименее ликвидной недвижимости предприятия этот период составляет около двух лет. Он включает в себя время подготовки активов и продажи, доведения информации о продаже до потенциальных покупателей, на обдумывание решения о покупке, аккумулирование финансовых средств на покупку, собственно покупку, перевозку и т. д.
Упорядоченной ликвидации активов соответствует понятие «упорядоченная ликвидационная стоимость предприятия».
В отличие от упорядоченной существует принудительная ликвидация, когда активы распродаются так быстро, как это возможно, часто одновременно и на одном аукционе. Принудительной ликвидации соответствует принудительная ликвидационная стоимость.
В случае принятия решения о прекращении существования предприятия определяется ликвидационная стоимость прекращения существования активов предприятия. При этом активы не продаются, а списываются и уничтожаются, а на данном месте строится новое прогрессивное предприятие, способное дать значительный экономический или социальный эффект. Здесь стоимость предприятия представляет собой отрицательную величину, так как требует от владельца предприятия определенных затрат на ликвидацию активов.
При расчете ликвидационной стоимости в случае ликвидации предприятия к скорректированной рыночной стоимости необходимо прибавить затраты на его ликвидацию. Они включают в себя комиссионные риэлторов, оценщиков и юристов, административные издержки по поддержанию работы предприятия вплоть до завершения его ликвидации, выходные пособия и выплаты, расходы на перевозку проданных активов и др.
При расчете ликвидационной стоимости, вырученной от продажи активов, денежная сумма, очищенная от соответствующих затрат, дисконтируется на дату оценки по соответствующей ставке, учитывающей связанный с этой продажей риск. Как правило, ликвидационная стоимость предприятия как целого меньше, чем сумма выручки, полученная от раздельной распродажи его активов.
При формулировании окончательного вывода о ликвидационной стоимости предприятия необходимо проанализировать еще раз факторы, имеющие отношение к собственно имуществу, и расходы, связанные с уровнем управления предприятием.
Если банкротство предприятия обусловлено низким уровнем управления, то это обстоятельство не должно негативно отразиться на ликвидационной стоимости предприятия.
Если причинами банкротства являются высокая степень износа активной и пассивной частей активов предприятия, его местоположение, то эти факторы существенно снизят уровень ликвидационной стоимости предприятия.
При оценке ликвидационной стоимости необходимо разобраться в причинах банкротства, прежде чем формулировать окончательное мнение об оценке.
Глава 10 Методы сравнительных исследований — Справочник по оценке электронного здравоохранения: доказательный подход
10.1. Введение
При оценке электронного здравоохранения цель сравнительных исследований — выяснить, влияют ли групповые различия в принятии системы электронного здравоохранения на важные результаты. Эти группы могут различаться по своему составу, типу используемой системы и условиям, в которых они работают в течение определенного периода времени. Сравнения должны определить, существуют ли существенные различия для некоторых предопределенных показателей между этими группами, при одновременном контроле как можно большего количества условий, таких как состав, система, настройки и продолжительность.
В соответствии с типологией Фридмана и Вятта (2006), сравнительные исследования принимают объективный взгляд на то, что такие события, как использование и влияние системы электронного здравоохранения, могут быть определены, измерены и сравнены с помощью набора переменных, чтобы доказать или опровергнуть гипотеза. Для сравнительных исследований варианты дизайна — экспериментальный против наблюдательного и проспективный против ретроспективного. Качество сравнительных исследований электронного здравоохранения зависит от таких аспектов методологической разработки, как выбор переменных, размер выборки, источники систематической ошибки, искажающие факторы и соблюдение рекомендаций по качеству и отчетности.
В этой главе мы сосредотачиваемся на экспериментальных исследованиях как на одном из типов сравнительных исследований и их методологических соображениях, о которых сообщалось в литературе по электронному здравоохранению. Также включены три примера из практики, показывающие, как проводятся эти исследования.
10.2. Типы сравнительных исследований
Экспериментальные исследования — это один из типов сравнительных исследований, в которых выборка участников определяется и распределяется по различным условиям в течение определенного периода времени, а затем сравнивается на предмет различий.Примером может служить больница с двумя отделениями, где одному назначается система cpoe для обработки заказов на лекарства в электронном виде, в то время как другой продолжает свою обычную практику без cpoe. Участники подразделения, назначенного для cpoe, называются группой вмешательства, а участники, назначенные для обычной практики, — контрольной группой. Сравнение может быть ориентировано на производительность или результат, например, на соотношение обработанных правильных заказов или возникновение побочных эффектов лекарств в двух группах в течение заданного периода времени.Экспериментальные исследования могут быть рандомизированными или нерандомизированными. Они описаны ниже.
10.2.1. Рандомизированные эксперименты
В рандомизированном плане участников случайным образом распределяют по двум или более группам с использованием известного метода рандомизации, такого как таблица случайных чисел. Дизайн носит перспективный характер, поскольку группы назначаются одновременно, после чего применяется вмешательство, затем измеряется и сравнивается. Ниже описаны три типа экспериментальных планов, используемых при оценке электронного здравоохранения (Friedman & Wyatt, 2006; Zwarenstein & Treweek, 2009).
Рандомизированные контролируемые испытания ( rct s) — Участники исследования случайным образом распределяются по группе вмешательства или контрольной группе. Рандомизация может происходить на уровне пациента, поставщика или организации, который известен как единица распределения. Например, на уровне пациента можно случайным образом назначить половине пациентов получать напоминания EMR, а другой половине — нет. На уровне поставщика можно назначить половину поставщиков для получения напоминаний, в то время как другая половина продолжает свою обычную практику.На уровне организации, например, в многопрофильной больнице, можно случайным образом назначить напоминания EMR некоторым сайтам, но не другим.
Кластерные рандомизированные контролируемые испытания (crcts) — В crcts группы участников рандомизированы, а не по отдельности, поскольку они находятся в естественных группах, например, живущих в одних и тех же сообществах. Например, клиники в одном городе могут быть рандомизированы в кластер для получения напоминаний об EMR, в то время как клиники в другом городе продолжают свою обычную практику.
Прагматические испытания — В отличие от программ, которые стремятся выяснить, работает ли вмешательство, такое как система cpoe, в идеальных условиях, практические испытания предназначены для выяснения того, работает ли вмешательство в обычных условиях. Цель состоит в том, чтобы сделать дизайн и выводы актуальными и практичными для лиц, принимающих решения, для применения в обычных условиях. Таким образом, прагматические испытания имеют несколько критериев для отбора участников исследования, гибкость в реализации вмешательства, обычную практику в качестве компаратора, такое же соблюдение и последующую интенсивность, что и в обычной практике, и результаты, которые важны для лиц, принимающих решения.
10.2.2. Нерандомизированные эксперименты
Нерандомизированный план используется, когда нецелесообразно и неэтично распределить участников по группам для сравнения. Иногда это называют квазиэкспериментальным дизайном. Дизайн может включать использование перспективных или ретроспективных данных от тех же или разных участников, что и контрольная группа. Ниже описаны три типа нерандомизированных планов (Harris et al., 2006).
Группа вмешательства только с предварительным и послетестовым дизайном — Этот план включает только одну группу, в которой предварительная или базовая мера принимается в качестве контрольного периода, вмешательство осуществляется, а мера после тестирования принимается в качестве контрольного периода. период вмешательства для сравнения.Например, можно сравнить частоту ошибок при приеме лекарств до и после внедрения системы cpoe в больнице. Чтобы повысить качество исследования, можно добавить второй период предварительного тестирования, чтобы уменьшить вероятность того, что разница между предварительным и послетестовым тестом является случайной, например, необычно низкой частотой ошибок при приеме лекарств в первом предварительном периоде. Другие способы повышения качества исследования включают добавление несвязанного результата, такого как набор случаев пациентов, на который не следует влиять, удаление вмешательства, чтобы увидеть, сохраняется ли разница, и удаление, а затем повторное внедрение вмешательства, чтобы увидеть, изменяются ли различия соответственно.
Вмешательство и контрольные группы с пост-тестовым дизайном — Этот план включает две группы, где вмешательство осуществляется в одной группе и сравнивается со второй группой без вмешательства, на основе пост-тестовых измерений из обеих групп. Например, можно внедрить систему cpoe в одном отделении в качестве группы вмешательства со вторым отделением в качестве контрольной группы и сравнить частоту ошибок приема лекарств после тестирования в обоих отделениях в течение шести месяцев. Чтобы повысить качество исследования, можно добавить один или несколько периодов предварительного тестирования в обе группы или применить вмешательство в контрольную группу позже, чтобы измерить аналогичные, но отсроченные эффекты.
Прерванный временной ряд ( его ) Дизайн — В его дизайне несколько мер принимаются из одной группы через равные промежутки времени, прерываясь осуществлением вмешательства. Множественные предварительные и послестестовые меры уменьшают вероятность того, что обнаруженные различия вызваны случайными или несвязанными эффектами. В качестве примера можно взять шесть последовательных ежемесячных показателей ошибок при приеме лекарств в качестве предварительных мер, внедрить систему cpoe, а затем взять еще шесть последовательных ежемесячных коэффициентов ошибок при приеме лекарств в качестве пост-тестовых мер для сравнения различий в частоте ошибок за 12 месяцев.Чтобы повысить качество исследования, можно добавить параллельную контрольную группу для сравнения, чтобы быть более уверенным в том, что вмешательство произвело изменение.
10.3. Методологические соображения
Качество сравнительных исследований зависит от их внутренней и внешней достоверности. Внутренняя валидность — это степень, в которой можно сделать правильные выводы из условий исследования, участников, вмешательства, измерений, анализа и интерпретаций. Внешняя достоверность относится к степени, в которой выводы могут быть обобщены на другие параметры.Ниже описаны основные факторы, влияющие на достоверность.
10.3.1. Выбор переменных
Переменные — это особые измеримые характеристики, которые могут влиять на достоверность. В сравнительных исследованиях выбор зависимых и независимых переменных и того, являются ли они категориальными и / или непрерывными по значениям, может повлиять на тип вопросов, дизайн исследования и анализ, которые необходимо учитывать. Они описаны ниже (Friedman & Wyatt, 2006).
Зависимые переменные — Это относится к интересующим результатам; они также известны как переменные результата.Примером может служить количество ошибок при приеме лекарств как результат определения того, может ли cpoe повысить безопасность пациентов.
Независимые переменные — Это относится к переменным, которые могут объяснить измеренные значения зависимых переменных. Например, характеристики обстановки, участников и вмешательства могут влиять на эффекты cpoe.
Категориальные переменные — это переменные с измеренными значениями в дискретных категориях или уровнях.Примерами являются тип провайдера (например, медсестры, врачи и фармацевты), наличие или отсутствие заболевания и шкала боли (например, от 0 до 10 с шагом 1). Категориальные переменные анализируются с использованием непараметрических методов, таких как хи-квадрат и отношение шансов.
Непрерывные переменные — это переменные, которые могут принимать бесконечные значения в пределах интервала, ограниченного только желаемой точностью. Примеры: артериальное давление, частота сердечных сокращений и температура тела. Непрерывные переменные анализируются с использованием параметрических методов, таких как t -тест, дисперсионный анализ или множественная регрессия.
10.3.2. Размер выборки
Размер выборки — это количество участников, которых нужно включить в исследование. Он может относиться к пациентам, поставщикам услуг или организациям в зависимости от того, как определяется единица распределения. Расчет размера выборки состоит из четырех частей. Они описаны ниже (Noordzij et al., 2010).
Уровень значимости — Это относится к вероятности того, что положительный результат является исключительно случайным. Обычно он устанавливается на 0,05, что означает, что вероятность ложноположительного заключения составляет менее 5%.
Мощность — это способность обнаруживать истинный эффект на основе выборки из совокупности. Обычно он равен 0,8, что означает, что вероятность сделать правильный вывод составляет не менее 80%.
Размер эффекта — Это относится к минимальной клинически значимой разнице, которая может быть обнаружена между группами сравнения. Для непрерывных переменных эффект представляет собой числовое значение, например разницу в весе в 10 кг между двумя группами. Для категориальных переменных это процентное значение, такое как 10% разница в частоте ошибок при приеме лекарств.
Вариабельность — Это относится к популяционной дисперсии интересующего результата, которая часто неизвестна и оценивается посредством стандартного отклонения (sd) из пилотных или предыдущих исследований для непрерывного результата.
Таблица 10.1
Уравнения размера выборки для сравнения двух групп с непрерывными и категориальными переменными результата.
Пример расчета размера выборки для исследования влияния КД на улучшение систолического артериального давления у пациентов с гипертонией приведен в Приложении.Посетите веб-сайт Biomath Колумбийского университета (без даты), чтобы узнать о простом веб-калькуляторе размера выборки / мощности.
10.3.3. Источники предвзятости
В сравнительных исследованиях есть пять распространенных источников предвзятости. Это отбор, производительность, выявление, отсев и предвзятость в отчетности (Higgins & Green, 2011). Эти предубеждения и способы их минимизации описаны ниже (Vervloet et al., 2012).
Ошибка отбора или распределения — Это относится к различиям между составом групп сравнения с точки зрения реакции на вмешательство.Примером может служить наличие более больных или пожилых пациентов в контрольной группе, чем в группе вмешательства, при оценке эффекта напоминаний EMR. Чтобы уменьшить систематическую ошибку отбора, можно применить рандомизацию и скрытие при распределении участников по группам и убедиться, что их составы сопоставимы на исходном уровне.
Систематическая ошибка — Это относится к различиям между группами в получаемой помощи, помимо оцениваемого вмешательства. Примером могут служить различные способы, с помощью которых напоминания запускаются и используются внутри и между группами, например электронные, бумажные и телефонные напоминания для пациентов и поставщиков медицинских услуг.Чтобы уменьшить предвзятость результатов, можно стандартизировать вмешательство и ослепить участников, зная, было ли вмешательство получено и какое вмешательство было получено.
Ошибка обнаружения или измерения — Это относится к различиям между группами в способах определения результатов. Примером может служить то, когда оценщики результатов уделяют больше внимания исходам пациентов, о которых известно, что они находятся в группе вмешательства. Чтобы уменьшить предвзятость при обнаружении, можно скрыть от участников оценщика при измерении результатов и обеспечить одинаковое время для оценки по всем группам.
Систематическая ошибка отсева — Это относится к различиям между группами в способах исключения участников из исследования. Примером может служить низкий уровень отклика участников в группе вмешательства, несмотря на то, что они получили напоминания о последующем уходе. Чтобы уменьшить систематическую ошибку отсева, необходимо учитывать процент отсева и анализировать данные в соответствии с принципом намерения лечить (т. Е. Включать в анализ данные тех, кто выбыл из школы).
Ошибка в отчетности — Это относится к различиям между отчетными и незарегистрированными результатами.Примеры включают предвзятость в публикации, временную задержку, цитирование, язык и отчет о результатах в зависимости от характера и направления результатов. Чтобы уменьшить систематическую ошибку в отчетности, можно сделать доступным протокол исследования со всеми заранее заданными результатами и сообщить обо всех ожидаемых результатах в опубликованных результатах.
10.3.4. Confounders
Confounders — это факторы помимо интересующего вмешательства, которые могут исказить эффект, поскольку они связаны как с вмешательством, так и с результатом.Например, в исследовании, чтобы продемонстрировать, привело ли принятие системы ввода заказов на лекарства к снижению затрат на лекарства, может быть ряд потенциальных факторов, которые могут повлиять на результат. Они могут включать в себя тяжесть заболевания пациентов, знания и опыт работы с системой, а также политику больницы по назначению лекарств (Harris et al., 2006). Другой пример — оценка влияния системы напоминаний об антибиотиках на частоту послеоперационных тромбозов глубоких вен (dvts).Факторами могут быть общие улучшения в клинической практике во время исследования, такие как схемы назначения лекарств и послеоперационный уход, которые не связаны с напоминаниями (Friedman & Wyatt, 2006).
Для контроля смешивающих эффектов можно рассмотреть использование сопоставления, стратификации и моделирования. Сопоставление включает выбор похожих групп по составу и поведению. Стратификация включает разделение участников на подгруппы по выбранным переменным, таким как индекс коморбидности для контроля тяжести заболевания.Моделирование включает использование статистических методов, таких как множественная регрессия, для корректировки воздействия конкретных переменных, таких как возраст, пол и / или тяжесть заболевания (Higgins & Green, 2011).
10.3.5. Руководство по качеству и отчетности
Существуют руководящие принципы по качеству и отчетности о сравнительных исследованиях. Руководящие принципы оценки (оценка, разработка и оценка рекомендаций) предоставляют явные критерии для оценки качества исследований в рандомизированных испытаниях и обсервационных исследованиях (Guyatt et al., 2011). Заявления расширенного консорта (Сводные стандарты отчетности об испытаниях) для нефармакологических испытаний (Boutron, Moher, Altman, Schulz, & Ravaud, 2008), прагматических испытаний (Zwarestein et al., 2008) и вмешательств в области электронного здравоохранения (Baker et al. , 2010) предоставляют рекомендации по составлению отчетов для рандомизированных исследований.
Руководства по оценкам предлагают систему оценки качества доказательств в систематических обзорах и руководствах. При таком подходе для поддержки оценок эффектов вмешательства rcts начинаются как доказательства высокого качества, а обсервационные исследования — как доказательства низкого качества.Для каждого результата исследования пять факторов могут снизить качество доказательств. Окончательное качество доказательств для каждого исхода может быть высоким, средним, низким и очень низким. Эти факторы перечислены ниже (подробнее о рейтинговой системе см. Guyatt et al., 2011).
Ограничения дизайна — Для случаев они охватывают отсутствие сокрытия распределения, отсутствие слепого анализа, значительную потерю для последующего наблюдения, преждевременное прекращение исследования или выборочную отчетность о результатах.
Несоответствие результатов — Вариации результатов из-за необъяснимой неоднородности. Примером может служить неожиданное изменение эффектов в разных подгруппах пациентов в зависимости от тяжести заболевания при использовании напоминаний о профилактической помощи.
Косвенность доказательств — Опора на косвенные сравнения из-за ограничений в исследуемых популяциях, вмешательстве, компараторе или исходах. Примером может служить 30-дневный показатель повторной госпитализации как суррогатный результат качества компьютерной неотложной помощи в больницах.
Неточность результатов — Исследования с небольшим размером выборки и небольшим количеством событий обычно имеют широкие доверительные интервалы и считаются низкокачественными.
Ошибка публикации — Выборочное сообщение результатов на уровне отдельного исследования уже охвачено ограничениями дизайна, но включено сюда для полноты, поскольку это актуально при оценке качества доказательств по всем исследованиям в систематических обзорах.
В исходном Заявлении о консорте есть 22 пункта контрольного списка для составления отчетов.Для нефармакологических исследований были расширены 11 позиций. Для прагматических испытаний были расширены до восьми пунктов. Эти предметы перечислены ниже. Для получения дополнительной информации читатели могут обратиться к Boutron et al. (2008) и на веб-сайте консорта (consort, n.d.).
Заголовок и аннотация — один пункт об использованных средствах рандомизации.
Введение — один пункт о предыстории, обосновании и проблеме, решаемой в ходе вмешательства.
Методы — 10 пунктов по участникам, вмешательствам, целям, результатам, размеру выборки, рандомизации (создание последовательности, сокрытие распределения, реализация), маскировке (маскирование) и статистическим методам.
Результаты — семь пунктов по потоку участников, набору, исходным данным, проанализированным числам, исходам и оценке, дополнительному анализу, нежелательным явлениям.
Обсуждение — три пункта по интерпретации, обобщаемости, общему доказательству.
Заявление консорта для вмешательств в области электронного здравоохранения описывает актуальность рекомендаций консорта для разработки и отчетности исследований электронного здравоохранения с акцентом на вмешательства в Интернете для непосредственного использования пациентами, такие как онлайн-ресурсы медицинской информации, помощники по принятию решений и phrs.Особое значение имеет необходимость четко определить компоненты вмешательства, их роль в общем процессе оказания помощи, целевую группу населения, процесс реализации, первичные и вторичные результаты, знаменатели для анализа результатов и потенциал реального мира (подробности см. В Baker et al. , 2010).
10.4. Примеры случаев
10.4.1. Прагматическое РКИ в поддержку принятия решений о сосудистом риске
Холбрук и его коллеги (2011) провели прагматическое исследование, чтобы изучить влияние КДС на лечение сосудов и исходы для пожилых людей.Краткое содержание исследования приводится ниже.
Организация — Практика первичной медико-санитарной помощи на уровне общины с EMR в одной канадской провинции.
Участники — англоговорящие пациенты в возрасте 55 лет и старше с диагностированным сосудистым заболеванием, без когнитивных нарушений и не проживающие в доме престарелых, которые посещали медработник в течение последних 12 месяцев.
Intervention — Интернет-система индивидуализированного сосудистого отслеживания и рекомендаций по восьми основным факторам риска сердечно-сосудистых заболеваний и двум факторам риска диабета, для использования как поставщиками медицинских услуг, так и пациентами и их семьями.Провайдеры и персонал могли обновлять профиль пациента в любое время, а алгоритм компакт-дисков запускался каждую ночь, чтобы обновлять рекомендации и цветовое выделение, используемое в интерфейсе трекера. Пациенты, которым проводилось вмешательство, имели доступ к трекеру в Интернете, печатную версию, отправленную им по почте до визита, и поддержку по телефону для получения рекомендаций.
Дизайн — Практичный, рассчитанный на один год, с двумя участниками, многоцентровый, с рандомизацией по согласию пациента по телефону, с использованием онлайн-программы со скрытым распределением. Рандомизация проводилась пациентом со стратификацией по поставщику с использованием блока размером шесть.Обученные рецензенты изучили данные EMR и провели телефонные интервью с пациентами для сбора факторов риска, сосудистого анамнеза и сосудистых событий. Провайдеры заполнили анкеты по вмешательству в конце исследования. Пациенты прошли последние 12-месячные лабораторные анализы на уровень альбумина в моче, холестерина липопротеинов низкой плотности и A1c.
Результаты — Первичный результат был основан на совокупном балле изменения процесса (ПК), рассчитанном как сумма взвешенных по частоте баллов процесса для каждого из восьми основных факторов риска с максимальным баллом 27.Процесс считался выполненным, если был проверен фактор риска. ПК измеряли на исходном уровне и в конце исследования с разницей в индивидуальных баллах первичного результата. Основным вторичным результатом был клинический сводный балл (ccs), основанный на тех же восьми факторах риска, сравниваемых двумя способами: сравнение среднего числа клинических переменных в целевом показателе и процента пациентов с улучшением между двумя группами. Другими вторичными исходами были фактическая частота сердечно-сосудистых событий, отдельные компоненты ПК и СК, оценки удобства использования, непрерывность лечения, способность пациента управлять сосудистым риском и качество жизни с использованием пятимерного опросника EuroQol (eq-5D).
Анализ — 1100 пациентов были необходимы для достижения 90% мощности в обнаружении одноточечной разницы ПК между группами со стандартным отклонением в пять баллов, двусторонний t -тест для средней разницы на уровне значимости 5%, и ставка вывода 10%. Баллы pcs, ccs и eq-5D были проанализированы с использованием обобщенного уравнения оценки, учитывающего кластеризацию внутри поставщиков. Описательная статистика и тесты χ2 или точные тесты проводились с другими исходами.
Результаты — В исследовании приняли участие 1102 пациента и 49 поставщиков медицинских услуг. В группе вмешательства с 545 пациентами наблюдалось значительное улучшение ЧС с разницей 4,70 ( p, <0,001) по 27-балльной шкале. В группе вмешательства также были значительно более высокие шансы повышения рейтинга непрерывности лечения (4,178, p <0,001) и способности улучшить состояние своих сосудов (3,07, p <0,001). Не было значительных изменений в сосудистых событиях, клинических показателях и качестве жизни.В целом вмешательство CDS привело к снижению сосудистого риска, но не к улучшению клинических результатов в течение одного года наблюдения.
10.4.2. Нерандомизированный эксперимент по назначению антибиотиков в первичной медицинской помощи
Mainous, Lambourne и Nietert (2013) провели проспективное нерандомизированное исследование, чтобы изучить влияние системы CD на назначение антибиотиков при острых респираторных инфекциях (aris) в первичной медико-санитарной помощи. Краткое содержание исследования приводится ниже.
Настройка — Исследовательская сеть первичной медико-санитарной помощи в США, члены которой используют общий EMR и ежеквартально объединяют данные для улучшения качества и проведения исследований.
Участники — группа вмешательства с девятью практиками в девяти штатах и контрольная группа с 61 практикой.
Intervention — Инструмент компакт-дисков для пунктов обслуживания в виде настраиваемых шаблонов заметок о ходе выполнения, основанных на существующих функциях EMR. Рекомендации CDS отражают рекомендации Центра по контролю и профилактике заболеваний (CDC), основанные на преобладающих симптомах и возрасте пациента. Компакт-диски использовались для помощи в постановке диагноза, своевременном применении антибиотиков, записи диагноза и решениях о лечении, а также для доступа к печатным ресурсам по обучению пациентов и медицинских работников с компакт-диска.
Дизайн — Группа вмешательства получила комплексное вмешательство для облегчения принятия CD поставщиками, которое включало ежеквартальный аудит и обратную связь, встречи по распространению передового опыта, посещение объектов с подробным академическим описанием, обзор эффективности и обучение CD. Контрольная группа не получала информации о вмешательстве, компакт-дисках или образовании. Сбор исходных данных продолжался три месяца с последующим наблюдением в течение 15 месяцев после внедрения CD.
Результаты — Результатами были частота неправильного назначения во время эпизода ari, использование антибиотиков широкого спектра действия и изменение диагностики.Неправильное назначение было рассчитано путем деления количества эпизодов ari с диагнозом несоответствующей категории, для которых был назначен антибиотик, на общее количество эпизодов ari с диагнозом, для которого антибиотики не подходят. Использование антибиотиков широкого спектра действия рассчитывалось по всем эпизодам ari с назначением антибиотиков широкого спектра действия по общему количеству эпизодов ari с назначением антибиотика. Дрейф антибиотиков рассчитывался двумя способами: делением количества эпизодов ari с диагнозами, при которых назначаются антибиотики, на общее количество эпизодов ari с назначением антибиотика; и деление количества эпизодов ari, в которых антибиотики не подходили, на общее количество эпизодов ari.Измерение процесса включало частоту использования шаблона компакт-дисков и то, различались ли показатели результатов в зависимости от использования компакт-дисков.
Анализ — Результаты измерялись ежеквартально для каждой практики, взвешиваясь по количеству эпизодов ari в течение квартала, чтобы придать больший вес практикам с большим количеством соответствующих эпизодов и периодам с большим количеством соответствующих эпизодов. Средневзвешенные значения и 95% цис рассчитывались отдельно для взрослых и детей (младше 18 лет) для каждого периода времени для обеих групп.Исходные средние показатели результатов сравнивались между двумя группами с использованием взвешенных тестов t для независимой выборки. Для сравнения изменений за 18-месячный период использовались линейные смешанные модели. Модели включали время, статус вмешательства и были скорректированы с учетом характеристик практики, таких как специальность, размер, регион и исходный уровень. Случайные эффекты практики были включены для учета кластеризации повторных измерений на практике с течением времени. P — значения менее 0,05 считались значимыми.
Результаты — Для взрослых пациентов количество неадекватных назначений во время эпизодов АРИ снизилось в большей степени в группе вмешательства (-0,6%), чем в контрольной группе (4,2%) ( p = 0,03), а назначение антибиотиков широкого спектра действия снизилось. на 16,6% в группе вмешательства по сравнению с увеличением на 1,1% в контрольной группе ( p <0,0001). Для педиатрических пациентов наблюдалось аналогичное снижение на 19,7% в группе вмешательства по сравнению с увеличением на 0,9% в контрольной группе ( p <0.0001). Подводя итог, можно сказать, что КДС оказали умеренное влияние на снижение количества нецелесообразных назначений взрослым, но имели существенный эффект на сокращение назначения антибиотиков широкого спектра действия взрослым и педиатрическим пациентам.
10.4.3. Прерванный временной ряд по влиянию EHR на медсестринский уход
Даудинг, Терли и Гарридо (2012) провели проспективное исследование, чтобы изучить влияние внедрения ehr на процессы и результаты сестринского ухода. Краткое содержание исследования приводится ниже.
Настройка — Kaiser Permanente (kp) как крупная некоммерческая интегрированная организация здравоохранения в США.
Участники — больницы 29 kp в северных и южных регионах Калифорнии.
Вмешательство — Интегрированная система ehr, внедренная во всех больницах с cpoe, медсестринской документацией и инструментами оценки рисков. Компонент медсестер для документации по оценке риска пролежней и падений был согласован во всех больницах и разработан клиническими медсестрами и специалистами по информатике на основе консенсуса.
Дизайн — его дизайн с ежемесячными данными о пролежнях и ежеквартальными данными о скорости падения и риске, собранными за семь лет в период с 2003 по 2009 год.Все данные были собраны на уровне отделения для каждой больницы.
Результаты — Измерения процесса включали долю пациентов, у которых была проведена оценка риска падения, и доля пациентов, у которых была проведена оценка риска госпитальной пролежни (hapu) в течение 24 часов с момента поступления. В качестве показателей результатов использовались показатели падения и hapu в рамках процесса сестринского ухода на уровне отделения, а также важные данные о результатах, которые регулярно собирались для всех больниц Калифорнии. Частота падений определялась как количество незапланированных спусков на пол на 1000 пациенто-дней, а hapu rate — это процент пациентов со стадиями i-IV или неэтапной язвой в день сбора данных.
Анализ — Данные о рисках падений и hapu были синхронизированы с использованием месяца, в котором ehr была внедрена в каждой больнице, в качестве нулевого времени и агрегированы по больницам для каждого периода времени. Для изучения влияния времени, региона и ehr использовался многомерный регрессионный анализ.
Результаты — ehr был связан со значительным увеличением количества документов для риска хапу (2,21; 95% ДИ от 0,67 до 3,75) и незначительным увеличением риска падения (0,36; -3.58 до 4.30). Ehr был связан с 13% -ным снижением скорости hapu (-0,76; -1,37 до -0,16), но без изменений в скорости падения (-0,091; -0,29 до 011). Район больницы был значимым предиктором вариаций для hapu (0,72; от 0,30 до 1,14) и частоты падений (0,57; от 0,41 до 0,72). В течение периода исследования частота hapu значительно снизилась (-0,16; -0,20 до -0,13), но не снизилась (0,0052; -0,01 до 0,02). Таким образом, внедрение ehr было связано с уменьшением числа падений hapus, но не с падением пациентов, и изменения со временем и регионом больницы также повлияли на результаты.
10,5. Резюме
В этой главе мы представили рандомизированные и нерандомизированные экспериментальные планы как два типа сравнительных исследований, используемых при оценке электронного здравоохранения. Рандомизация — это самый качественный дизайн, поскольку он снижает систематическую ошибку, но это не всегда возможно. Рассматриваемые методологические вопросы включают выбор переменных, размер выборки, источники систематических ошибок, искажающие факторы и соблюдение руководящих принципов отчетности. Были включены три тематических примера, чтобы показать, как проводятся сравнительные исследования электронного здравоохранения.
- Бейкер Т. Б., Густафсон Д. Х., Шоу Б., Хокинс Р., Пингри С., Робертс Л., Стречер В. Актуальность критериев отчетности супругов для исследований в области электронного здравоохранения. Обучение и консультирование пациентов. 2010; 81 (доп. 7): 77–86. [Бесплатная статья PMC: PMC2993846] [PubMed: 20843621]
- Колумбийский университет. (нет данных). Статистика: размер выборки / расчет мощности. Biomath (Отделение биоматематики / биостатистики), педиатрическое отделение. Нью-Йорк: Медицинский центр Колумбийского университета.Получено с http: // www
- Бутрон И., Мохер Д., Альтман Д. Г., Шульц К. Ф., Раво П. consort Group. Распространение заявления консорта на рандомизированные испытания нефармакологического лечения: объяснение и уточнение. Анналы внутренней медицины. 2008. 148 (4): 295–309. [PubMed: 18283207]
- Даудинг Д. В., Терли М., Гарридо Т. Влияние электронной истории болезни на результаты лечения пациентов, чувствительные к медсестре: анализ прерывистого временного ряда.Журнал Американской ассоциации медицинской информатики. 2012. 19 (4): 615–620. [Бесплатная статья PMC: PMC3384108] [PubMed: 22174327]
Фридман К. П., Вятт Дж. Методы оценки в биомедицинской информатике. 2-е изд. Нью-Йорк: Springer Science + Business Media, Inc; 2006.
- Guyatt G., Oxman A. D., Akl E. A., Kunz R., Vist G., Brozek J. et al. Schunemann H.J. Руководство по классам: 1. Введение — профили доказательств оценки и сводные таблицы результатов. Журнал клинической эпидемиологии.2011. 64 (4): 383–394. [PubMed: 21195583]
- Харрис А. Д., МакГрегор Дж. К., Переневич Э. Н., Фуруно Дж. П., Чжу Дж., Петерсон Д. Э., Финкельштейн Дж. Использование и интерпретация квазиэкспериментальных исследований в медицинской информатике. Журнал Американской ассоциации медицинской информатики. 2006. 13 (1): 16–23. [Бесплатная статья PMC: PMC1380192] [PubMed: 16221933]
- Кокрановское сотрудничество. Кокрановское руководство для систематических обзоров вмешательств. Хиггинс Дж. П. Т., Грин С., редакторы. Лондон: 2011.(Версия 5.1.0, обновлено в марте 2011 г.) Получено из http: // handbook
- Холбрук А., Пулленайегум Э., Табане Л., Троян С., Фостер Г., Кешавджи К. и другие. Curnew G. Совместная электронная поддержка принятия решений о сосудистых рисках в первичной медико-санитарной помощи. Компьютеризация медицинской практики для повышения терапевтической эффективности (конкуренция III) рандомизированное исследование. Архивы внутренней медицины. 2011. 171 (19): 1736–1744. [PubMed: 22025430]
- Майноус III А. Г., Ламбурн К.А., Нитерт П.Дж.Влияние системы поддержки принятия клинических решений на назначение антибиотиков при острых респираторных инфекциях в первичной медико-санитарной помощи: квазиэкспериментальное исследование. Журнал Американской ассоциации медицинской информатики. 2013. 20 (2): 317–324. [Бесплатная статья PMC: PMC3638170] [PubMed: 22759620]
- Vervloet M., Linn AJ, van Weert JCM, de Bakker DH, Bouvy ML, van Dijk L. лекарства: систематический обзор литературы.Журнал Американской ассоциации медицинской информатики. 2012. 19 (5): 696–704. [Бесплатная статья PMC: PMC3422829] [PubMed: 22534082]
- Zwarenstein M., Treweek S., Gagnier JJ, Altman DG, Tunis S., Haynes B., Oxman AD, Moher D. для консортных и прагматических испытаний в здравоохранении (Практические) группы. Улучшение отчетности о прагматических испытаниях: расширение заявления консорта. Британский медицинский журнал. 2008; 337: а2390. [Бесплатная статья PMC: PMC3266844] [PubMed: 1
84] [CrossRef]
Приложение.Пример расчета размера выборки
Это пример расчета размера выборки для rct, который исследует влияние системы CD на снижение систолического артериального давления у пациентов с гипертонией. Случай адаптирован из примера, описанного в публикации Noordzij et al. (2010).
(a) Систолическое артериальное давление как непрерывный результат, измеряемый в мм рт. .Оценщик желает обнаружить клинически значимую разницу в 15 мм рт.ст. систолического артериального давления как результат между группой вмешательства с КДС и контрольной группой без КДС. Если принять уровень значимости или альфа 0,05 для двустороннего критерия t и степень 0,80, соответствующие множители 1 равны 1,96 и 0,842 соответственно. Используя приведенное ниже уравнение размера выборки для непрерывного результата, мы можем рассчитать размер выборки, необходимый для вышеуказанного исследования.
n = 2 [(a + b) 2σ2] / (μ1-μ2) 2, где
n = размер выборки для каждой группы
μ1 = среднее значение систолического артериального давления в группе вмешательства
μ2 = среднее значение для населения систолическое артериальное давление в контрольной группе
μ1- μ2 = желаемая разница средних систолических артериальных давлений между группами
σ = популяционная дисперсия
a = множитель уровня значимости (или альфа)
b = множитель мощности (или 1- beta)
Ввод значений в уравнение даст размер выборки (n) из 28 выборок на группу, в результате
n = 2 [(1.96 + 0,842) 2 (202)] / 152 или 28 образцов на группу
(b) Систолическое артериальное давление как категориальный результат, измеренный как ниже или выше 140 мм рт.ст. (т.е. гипертония да / нет)
В этом примере систолическое давление артериальное давление в образце, превышающее 140 мм рт. ст., считается событием у пациента с гипертонией. Согласно опубликованной литературе, доля пациентов с артериальной гипертензией в общей популяции составляет 30%. Оценщик желает обнаружить клинически значимую разницу в 10% систолического артериального давления как результат между группой вмешательства с КДС и контрольной группой без КДС.Это означает, что ожидаемая доля пациентов с артериальной гипертензией составляет 20% (p1 = 0,2) в группе вмешательства и 30% (p2 = 0,3) в контрольной группе. При уровне значимости или альфа 0,05 для двустороннего критерия t и степени 0,80 соответствующие множители равны 1,96 и 0,842 соответственно. Используя приведенное ниже уравнение размера выборки для категориального результата, мы можем рассчитать размер выборки, необходимый для вышеуказанного исследования.
n = [(a + b) 2 (p1q1 + p2q2)] / χ2
n = размер выборки для каждой группы
p1 = доля пациентов с гипертонией в группе вмешательства
q1 = доля пациентов без гипертонии в группа вмешательства (или 1-p1)
p2 = доля пациентов с гипертонией в контрольной группе
q2 = доля пациентов без гипертонии в контрольной группе (или 1-p2)
χ = желаемая разница в доле пациентов с гипертонией между две группы
a = множитель для уровня значимости (или альфа)
b = множитель для степени (или 1-бета)
Приведя значения в уравнении, можно получить размер выборки (n) из 291 выборки на группу в качестве результат
n = [(1.96 + 0,842) 2 ((0,2) (0,8) + (0,3) (0,7))] / (0,1) 2 или 291 образец на группу
- 1
Из таблицы 3 на стр. 1392 из Noordzij et al. (2010).
Сравнительный анализ политологии
Каковы преимущества сравнения институтов и политических процессов в двух или более странах по сравнению с изучением одних и тех же институтов или процессов в одной стране?
Это эссе послужит кратким введением в практические, концептуальные и теоретические ценности сравнительного анализа в политической науке.После краткого объяснения методологии это эссе объяснит важность его роли и преимущества, которые оно приносит в области политических исследований. В эссе также будут рассмотрены преимущества сравнительного анализа институтов и процессов сопоставления в двух или более странах, а не в одной.
Сравнительный анализ (СА) — это методология в политической науке, которая часто используется при изучении политических систем, институтов или процессов. Это может быть сделано в местном, региональном, национальном и международном масштабе.Кроме того, CA основывается на эмпирических данных, собранных в результате регистрации и классификации реальных политических явлений. В то время как другие политические исследования разрабатывают политику посредством идеологического и / или теоретического дискурса, сравнительное исследование направлено на развитие более глубокого политического понимания с помощью научно ограниченной методологии. Часто упоминается как одна из трех крупнейших областей политической науки, эта область исследований была названа «величайшим интеллектуальным достижением» Эдвардом А.Фриман (Лейпхарт, Северная Дакота).
Используя сравнительную методологию, ученый может задавать вопросы различных политических проблем, таких как связь, если таковая имеется, между капитализмом и демократизацией или сопоставление между федеративными и унитарными государствами и участием в выборах. CA можно использовать как в одной стране (случай), так и в группе стран. Для того чтобы исследование одной страны считалось сравнительным, важно, чтобы результаты исследования были отнесены к более широкой структуре, которая включает систематическое сравнение аналогичных явлений.После применения сравнительной методологии к сопоставлению или сбору данных установленные гипотезы могут быть проверены в аналитическом исследовании, включающем несколько случаев (Caramani, 2011).
Шаблоны, сходства и различия исследуются для оценки взаимосвязи вариантов между двумя или более отдельными системами. Именно этот характер анализа делает его сравнительным. С этого момента исследователь может выделить независимые переменные в каждом случае исследования.Если независимые переменные «X» и «Y» существуют, их отношение к зависимой переменной «Z» можно предположить, проверить и установить (Landman, 2008). Эта изоляция важна для наиболее определяющей и значимой силы CA, то есть для установления гипотетических отношений между переменными (Guy, 2011). Этот эмпирический анализ можно использовать для объяснения системы, представления теоретических идей для модификации и даже для разумного прогнозирования будущих последствий рассматриваемого тематического исследования.
В то время как некоторые исследователи могут отдавать предпочтение большему количеству стран для своего исследования (большое N), другие будут использовать меньшее количество единиц (малое N) (Guy, 1988). Размер тематического исследования напрямую сопоставляется с предметом и должен придавать исследованию достаточную статистическую мощность. Исследователь решает, наиболее целесообразно изучить одну или несколько единиц для сравнения и следует ли использовать количественные или качественные методы исследования (Guy, 1988). Методология использования нескольких стран при анализе — это тесное копирование экспериментального метода, используемого в естествознании (Lim, 2010).Явной сильной стороной этого метода является включение возможности осуществлять статистический контроль для вычитания конкурирующих объяснений, его способность делать убедительные выводы, пригодные для большего числа случаев, и его способность классифицировать « девиантные » страны, которые противоречат результатам, ожидаемым от теории. проходит тестирование (Guy, 2011).
Девиантные страны или случаи — это единицы, которые кажутся исключениями из нормы анализируемой теории. Они наиболее распространены при изучении процессов и институтов с участием только одной страны.Это связано с тем, что часто проверяется строго ограниченное количество изменчивости (Lim, 2010). Проверяя связь между неравенством доходов и политическим насилием в шестидесяти странах, Мюллер и Селигсон определили, какие страны соответствуют их теории, а какие нет. В Бразилии, Панаме и Габоне уровень политического насилия оказался ниже, чем ожидалось для их национального уровня неравенства доходов. В качестве альтернативы, при низком национальном уровне неравенства доходов, в Великобритании уровень политического насилия оказался выше, чем ожидалось (Harro and Hauge, 2003). Эта идентификация этих «девиантных» случаев позволила исследователям искать объяснения. Они смогли вычесть их из своего анализа и повысить точность своих прогнозов для других случаев. Этого нельзя было достичь в исследовании одной страны, и результаты неизбежно оставались бы несбалансированными и неточными.
Систематическая ошибка отбора — это редуцирующая практика, которая наиболее распространена при исследованиях в одной стране. Он возникает из-за преднамеренного предубеждения стран, выбранных для исследования.Самая разрушительная форма предвзятости отбора для достоверности исследования — это когда анализируются только случаи, которые подтверждают гипотезу теории. Серьезная проблема смещения выборки встречается гораздо реже в исследованиях, охватывающих несколько стран (Lim, 2010). Это связано с тем, что исследования, сравнивающие институты и процессы в нескольких странах, часто полагаются на достаточное количество наблюдений, которые уменьшают проблему или, по крайней мере, ее последствия систематической ошибки отбора. Использование нескольких стран снижает риск явления, вызывающего инвалидность.
Однако исследование отдельной страны явно ценно; он может дать проницательное исследование многих внутренних институтов, таких как социальное здравоохранение, а также таких процессов, как иммиграция. Однако полученные результаты в основном применимы к стране анализа. Несмотря на то, что результаты многонационального СА также ценны внутри страны, они также имеют тенденцию быть более ценными по своей сути для более широкой международной области. Это связано с тем, что сопоставления многонациональных институтов и процессов, которые функционально сопоставлены, имеют более высокую глобальную валидность и переносимость, чем результаты сравнения для отдельной страны (Keman, 2011).Сравнительные результаты одной нации должны быть выдвинуты на основе гипотез с другим пониманием и предсказаниями, в значительной степени полагающимися на теоретические наблюдения, предположения и прошлые исследования. Неизбежно, что изучение более чем одной страны предоставляет исследованию более обширную область для анализа. Именно ЦС субъектов из многих стран может разрабатывать тематические карты, определять национальные, региональные и глобальные тенденции, а транснациональные организации могут принимать взвешенные решения. Эти практические преимущества невозможны при анализе явления в одной стране без сравнения между разными случаями.Анализ нескольких межнациональных единиц также способствует нашему пониманию сходств, различий и взаимосвязей между самим тематическим исследованием и геополитическими, экономическими и социокультурными факторами, которые в противном случае не учитывались бы.
Популярность сравнительного метода анализа двух или более стран неуклонно растет (Landman, 2008). В самом деле, это можно считать важным для понимания и развития современной теории политических и международных отношений.С постоянным распадом стран по всему миру, таких как Югославия и Чехословакия, в сочетании с потенциалом для создания новых государств, таких как Палестина; ЦА, в котором участвуют разные страны, предлагает массу информации и, самое главное, прогнозы их будущего. Эта теоретическая основа для предсказания бесценна для общества.
В качестве альтернативы анализ, применяемый к случаю отдельной страны, менее применим в глобальном масштабе (Lim, 2010). Например; Изучение процесса демократизации в одной латиноамериканской стране, хотя оно предлагает важные выводы, которые могут быть изучены в других странах с аналогичным набором обстоятельств, вероятно, недостаточно для разработки самой теории демократизации, которая была бы применима в глобальном масштабе.Проще говоря, единичный анализ учреждения или процесса, охватывающий только одну страну, часто не дает глобального набора выводов, позволяющих точно теоретизировать процесс (Harro and Hauge, 2003).
Сравнение и сопоставление процессов и институтов двух или более стран позволяет выделить конкретные национальные варианты (Hopkin, 2010). Он также поощряет четкое выявление общих сходств, тенденций и причинно-следственных связей и выведение ложной причинности. Это означает, что устоявшиеся гипотезы постоянно нуждаются в переоценке и модификации.Это позволяет исследователю свести к минимуму редуктивный феномен «слишком много переменных — недостаточно стран», это происходит, когда исследователь не может выделить зависимую переменную исследования из-за слишком большого количества потенциальных переменных (Harro and Hauge, 2003). Эта проблема в большей степени связана с исследованиями в одной стране, поскольку она является результатом избытка потенциальных объясняющих факторов в сочетании с недостаточным количеством стран или случаев в исследовании (Harro and Hauge, 2003).
Исследования с участием нескольких стран помогают определить результаты как идиографические по своей природе или номотетические (Franzese, 2007). Это также помогает провести важное различие между причинно-следственной связью, положительной корреляцией, отрицательной корреляцией и некорреляцией. При анализе только одного случая или страны труднее правильно провести различие между этими отношениями, особенно если они связаны не только с одной страной.
Именно изучая институты и процессы в разных странах с использованием эмпирической методологической основы, исследователь может делать выводы без двусмысленности обобщений.Разделение сравниваемых случаев предлагает исследователю более обширную базу для изучения переменных, которые помогают в тщательной проверке гипотез и в создании других. Именно через CA можно определить коррелирующие, зависимые и независимые отношения (Lim, 2010). Включение нескольких стран в исследование делает выводы более обоснованными (Keman, 2011). Например, Гурр продемонстрировал, что масштабы гражданских беспорядков в 114 странах напрямую связаны с существованием экономических и политических лишений.Эта теория верна для большинства стран, в которых она проверяется (Keman, 2011).
Следует также отметить, что все страны в разной степени функционируют во взаимозависимой глобализированной среде. Из-за иммиграционной, экономической и политической взаимозависимости изучение институтов и / или процессов в одной стране неизбежно снижает переносимость результатов. Это связано с тем, что результаты, по крайней мере, применимы для передачи настолько, насколько их аналоги функционально эквивалентны.Он также несколько не учитывает транснациональные тенденции (Franzese, 2007). С другой стороны, сравнение с участием нескольких стран, особенно с использованием количественных методов, может предложить ценные геополитические и внутренние обобщения, основанные на эмпирическом опыте. Они помогают в развитии нашего понимания политических явлений и дают отличные рекомендации о том, как продолжить конкретное исследование, используя одну и ту же форму анализа или другой метод вместе.
Исследование процессов и институтов в двух или более странах подвергалось критике за получение менее глубокой информации по сравнению с исследованиями с участием одной страны (Franzese, 2007).Хотя это кажется существенной критикой; Ученые не всегда соглашаются, что этот компромисс между количеством и качеством является существенным или даже чрезвычайно актуальным. Роберт Францезе утверждает, что относительная потеря деталей, возникающая в результате анализа большого количества международных дел, не оправдывает отступление к качественному изучению нескольких случаев (Franzese, 2007). Это связано с тем, что большинство обобщений из исследований по отдельной стране неизбежно будет ограниченным, поскольку страна как единица связана уникальными внутренними характеристиками.
Очевидно, что исследования как отдельных наций, так и многонациональных играют важную роль в ЦА. Тем не менее, как показано выше, преимущества включения нескольких стран в сравнительные исследования намного перевешивают любое снижение качества результатов. Действительно, многонациональные исследования работают над снижением систематической ошибки отбора и поощрением возможности глобального переноса, помогают в выводе переменных и получают признание как эмпирически научные.
Библиография
Карамани, Д.(2011) Введение в сравнительную политику. В: Даниэле Карамани (ред) «Сравнительная политика». 2-е издание. Лондон, Оксфорд: Издательство Оксфордского университета, стр. 1-19
Калпеппер, П. (2002) «Исследования отдельных стран и сравнительная политика», Кембридж, Массачусетс, издательство Гарвардского университета.
Францезе, Р. (2007) «Множественность, контекстно-условность и эндогенность» В: Карелс Бойс и Сьюзан Стоукс. изд. «Оксфордский справочник по политологии». Издательство Оксфордского университета: Нью-Йорк.pp29-72
Гай П. (1988) «Важность сравнения». В: « Comparative Politics Theory and Methods.» Basingstoke: Palgrave Macmillan. стр. 2-27
Гай П. (2011) «Подходы в сравнительной политике». В: Даниэле Карамани (ред) « Comparative Politics », 2-е издание. Лондон, Оксфорд: Oxford University Press, стр. 37-49
Харроп М. и Хауге Р. (2003) « Сравнительный подход» . Basingstoke: Palgrave Macmillan
Хопкин, Дж.(2010) «Сравнительный метод». В: Дэвид Марш и Джерри Стокер .ed (s) « Теория и методы в политической науке» . Бейзингстоук: Пэлгрейв Макмиллан. стр. 285-307
Кеман, Х. (2011) «Сравнительные методы исследования» . В Даниэле Карамани (ред) «Сравнительная политика». 2 -е издание . Лондон, Оксфорд: Издательство Оксфордского университета, стр. 50-63
Ландман Т. (2008) «Зачем сравнивать страны?». В: « Проблемы и методы в сравнительной политике: Введение .3-е изд. Лондон: Рутледж, стр. 3-22
Lijhart, A. (ND) « Сравнительная политика и сравнительная модель». In: ‘The American Polit Science Review ’ . Том 65, № 3. Нью-Йорк: Американская ассоциация политических наук, стр. 682-693
Лим, Т. (2010) «Проведение сравнительной политики: введение в подходы и проблемы» . 2 ое издание . Лондон: Линн Риннер
—
Автор: Александр Стаффорд
Написано: Королевский университет Белфаста
Написано для: доктор Элоди Фабр
Дата написания: февраль 2013 г.
Дополнительная литература по электронным международным отношениям
Подход сравнения продаж (SCA) Определение
Что такое подход сравнения продаж (SCA)?
Термин «подход сравнения продаж» относится к методу оценки недвижимости, который сравнивает одну недвижимость с сопоставимыми или другими недавно проданными объектами недвижимости в районе с аналогичными характеристиками.Агенты по недвижимости и оценщики могут использовать подход сравнения продаж при оценке недвижимости для продажи. Этот метод учитывает влияние отдельных функций на общую стоимость свойства. Другими словами, общая стоимость свойства — это сумма значений всех его характеристик.
Ключевые выводы
- Подход сравнения продаж — это метод оценки, используемый в сфере недвижимости, который сравнивает одну недвижимость с аналогичными, недавно проданными в этом районе.
- SCA используется в качестве основы для сравнительного анализа рынка, который учитывает цены на недавно проданные объекты недвижимости, которые похожи и находятся в одной и той же географической зоне.
- Некоторые из общих характеристик, составляющих SCA, включают местоположение, недавно проданные объявления, характеристики, возраст и состояние, а также среднюю цену за квадратный фут.
Понимание подхода сравнения продаж (SCA)
Подход сравнения продаж помогает профессионалам в сфере недвижимости и покупателям определить, является ли цена дома справедливой и сопоставимой с текущим рынком.Профессионалы используют аналогичные объекты недвижимости, которые недавно были проданы на небольшом расстоянии от объекта оценки — обычно в том же районе, — которые имеют аналогичные характеристики для сравнения.
SCA используется в качестве основы для сравнительного анализа рынка (CMA). Это анализ цен на недавно проданные объекты недвижимости, которые похожи и находятся в одной географической зоне. Другими словами, этот подход часто подразумевает изучение местной собственности, чтобы увидеть, что у них общего.Оттуда оценщики могут определить стоимость собственности на основе ее характеристик.
Несмотря на то, что оценщик недвижимости может предпринять множество шагов при оценке стоимости собственности, в SCA чаще всего используются следующие характеристики:
- Местоположение и окрестности: География может напрямую влиять на стоимость недвижимости. Важно сравнивать дома в одном районе, а не в другой части города.Учитываемые факторы включают близость к школам, близлежащим водоемам, паркам и их близость к автомагистралям и эстакадам, а также уровни загрязнения.
- Недавно проданных объявлений: Эти свойства могут служить отправной точкой для определения стоимости домов в этом районе. Несмотря на то, что характеристики и рынок влияют на цену продажи, анализ стоимости недвижимости и недавние продажи являются хорошими исходными показателями.
- Характеристики: Дом следует сравнивать с объектами с таким же количеством спален, гаражей и ванных комнат.Сравнение должно включать дома примерно одинаковой площади на земельных участках примерно одинакового размера.
- Возраст и состояние: Важно сравнивать дома аналогичного возраста, а также их надежность. Состояние дома существенно влияет на оценку. Например, в одном районе может быть два одинаковых дома. Но если кто-то нуждается в ремонте, это может серьезно повлиять на его стоимость.
- Средняя цена за квадратный фут: После составления списка похожих домов, возьмите каждую из продажных цен и разделите их на квадратные метры.Результат дает стоимость квадратного фута на основе домов в сравнительном анализе продаж. Возьмите среднюю стоимость квадратного фута для всех сопоставимых домов и умножьте это число на квадратные метры оцениваемого дома.
Особые соображения
Есть много других функций, которые могут повысить стоимость дома. Однако сравнительный анализ продаж не является точной наукой, поскольку стоимость дома в некоторой степени субъективна, что означает, что одна семья может найти в нем большую ценность, чем другая, тем самым увеличивая свое предложение.Как указывалось ранее, внешние факторы, такие как общее состояние экономики, рынок труда и состояние рынка недвижимости, в значительной степени влияют на то, сколько дом продается или как долго он находится на рынке.
Поскольку метод сравнения продаж не является официальной оценкой, владельцам может потребоваться нанять оценщика для уникальных свойств и тех, которые трудно оценить.
Но помните, что подход сравнения продаж, используемый при оценке недвижимости, не является официальной оценкой.В случаях, когда необходимо оценить уникальное свойство или имущество, стоимость которого трудно определить, может потребоваться формальная оценка. Это означает найм оценщика — независимого и беспристрастного профессионала, который определяет справедливую стоимость собственности, используя определенные факты, цифры и другие соображения.
Алгоритмы кластеризации: сравнительный подход
Abstract
Многие реальные системы можно изучать с точки зрения задач распознавания образов, поэтому правильное использование (и понимание) методов машинного обучения в практических приложениях становится важным.Хотя было предложено множество методов классификации, нет единого мнения о том, какие методы более подходят для данного набора данных. Как следствие, важно всесторонне сравнить методы во многих возможных сценариях. В этом контексте мы провели систематическое сравнение 9 хорошо известных методов кластеризации, доступных на языке R, предполагая, что данные распределены нормально. Чтобы учесть множество возможных вариаций данных, мы рассмотрели искусственные наборы данных с несколькими настраиваемыми свойствами (количество классов, разделение между классами и т. Д.).Кроме того, мы также оценили чувствительность методов кластеризации в отношении конфигурации их параметров. Результаты показали, что при рассмотрении конфигураций по умолчанию принятых методов спектральный подход, как правило, дает особенно хорошие характеристики. Мы также обнаружили, что конфигурация принятых реализаций по умолчанию не всегда была точной. В этих случаях простой подход, основанный на случайном выборе значений параметров, оказался хорошей альтернативой для повышения производительности.В целом, представленный подход предусматривает субсидии, определяющие выбор алгоритмов кластеризации.
Образец цитирования: Rodriguez MZ, Comin CH, Casanova D, Bruno OM, Amancio DR, Costa LdF, et al. (2019) Алгоритмы кластеризации: сравнительный подход. PLoS ONE 14 (1): e0210236. https://doi.org/10.1371/journal.pone.0210236
Редактор: Ханс А. Кестлер, Ульмский университет, ГЕРМАНИЯ
Поступила: 26.12.2016; Одобрена: 19 декабря 2018 г .; Опубликовано: 15 января 2019 г.
Авторские права: © 2019 Rodriguez et al.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Все наборы данных, используемые для оценки алгоритмов, можно получить на сайте Figshare: https://figshare.com/s/29005b491a418a667b22.
Финансирование: Эта работа была поддержана FAPESP — Fundação de Amparo à Pesquisa do Estado de São Paulo (гранты №15 / 18942-8 и 18 / 09125-4 для CHC, 14 / 20830-0 и 16 / 19069-9 для DRA, 14 / 08026-1 для OMB и 11 / 50761-2 и 15 / 22308-2 для LdFC) , CNPq — Conselho Nacional de Desenvolvimento Científico e Tecnológico (гранты № 307797 / 2014-7 для OMB и 307333 / 2013-2 для LdFC), Núcleo de Apoio à Pesquisa (LdFC) и CAPES — Superior Coordenação de Pesquisa (Финансовый код 001).
Конкурирующие интересы: Авторы заявили, что никаких конкурирующих интересов не существует.
Введение
В последние годы автоматизация сбора и записи данных потребовала огромного количества информации о многих различных типах систем [1–8].Как следствие, было разработано множество методологий, направленных на организацию и моделирование данных [9]. Такие методологии мотивированы их широким применением в диагностике [10], образовании [11], прогнозировании [12] и многих других областях [13]. Определение, оценка и применение этих методологий — все это часть области машинного обучения [14], которая стала важной областью информатики и статистики из-за их решающей роли в современном мире.
Машинное обучение охватывает различные темы, такие как регрессионный анализ [15], методы выбора признаков [16] и классификация [14].Последнее предполагает присвоение классов объектам в наборе данных. Для классификации можно рассмотреть три основных подхода: контролируемая, частично контролируемая и неконтролируемая классификация. В первом случае классы или метки некоторых объектов известны заранее, что определяет обучающий набор, и для получения критериев классификации используется алгоритм. Классификация с полууправлением занимается обучением алгоритма с использованием как помеченных, так и немеченых данных. Они обычно используются, когда ручная маркировка набора данных становится дорогостоящей.Наконец, неконтролируемая классификация, далее называемая кластеризацией , имеет дело с , определяющим классы из данных без знания меток классов. Целью алгоритмов кластеризации является выявление групп объектов или кластеров, которые больше похожи друг на друга, чем на другие кластеры. Такой подход к анализу данных тесно связан с задачей создания модели данных, то есть определения упрощенного набора свойств, который может предоставить интуитивно понятное объяснение соответствующих аспектов набора данных.Методы кластеризации обычно более требовательны, чем контролируемые подходы, но позволяют лучше понять сложные данные. Классификаторы этого типа составляют основной объект текущей работы.
Поскольку алгоритмы кластеризации включают несколько параметров, часто работают в многомерных пространствах и должны справляться с зашумленными, неполными и дискретизированными данными, их производительность может существенно различаться для разных приложений и типов данных. По этим причинам в литературе было предложено несколько различных подходов к кластеризации (например,г. [17–19]). На практике выбор подходящего подхода к кластеризации становится сложной задачей, учитывая набор данных или проблему. Тем не менее, можно многому научиться, сравнивая разные методы кластеризации. О нескольких предыдущих попытках сравнения алгоритмов кластеризации сообщалось в литературе [20–29]. Здесь мы сосредоточены на создании разнообразного и всеобъемлющего набора искусственных, нормально распределенных данных, содержащих не только определенное количество классов, функций, количество объектов и разделение между классами, но также разнообразную структуру задействованных групп (например,г. обладающие предопределенными распределениями корреляции между функциями). Целью использования искусственных данных является возможность получить неограниченное количество выборок и систематически изменять любое из вышеупомянутых свойств набора данных. Такие функции позволяют комплексно и строго оценивать алгоритмы кластеризации в большом количестве обстоятельств, а также предоставляют возможность количественной оценки чувствительности производительности по отношению к небольшим изменениям данных. Тем не менее, следует отметить, что результаты производительности, представленные в этой работе, поэтому являются соответствующими и ограничиваются нормально распределенными данными, и можно ожидать других результатов для других типов данных, следующих за другим статистическим поведением.Здесь мы связываем производительность со сходством между известными метками объектов и метками, найденными алгоритмом. Для количественной оценки такого сходства было определено множество измерений [30], мы сравниваем индекс Жаккара [31], скорректированный индекс Рэнда [32], индекс Фаулкса-Маллоуса [33] и нормализованную взаимную информацию [34]. Модифицированная версия процедуры, разработанная [35], была использована для создания 400 различных наборов данных, которые использовались для количественной оценки производительности алгоритмов кластеризации.Мы описываем принятую процедуру и соответствующие параметры, используемые для генерации данных. Связанные подходы включают [36].
Каждый алгоритм кластеризации основан на наборе параметров, которые необходимо настроить для достижения жизнеспособной производительности, что соответствует важному моменту, который необходимо учитывать при сравнении алгоритмов кластеризации. Давняя проблема в машинном обучении — определение правильной процедуры для установки значений параметров [37]. В принципе, можно применить процедуру оптимизации (например,g., моделирование отжига [38] или генетические алгоритмы [39]), чтобы найти конфигурацию параметров, обеспечивающую наилучшую производительность данного алгоритма. Тем не менее, у такого подхода есть две основные проблемы. Во-первых, корректировка параметров для данного набора данных может привести к переобучению [40]. То есть определенные значения, обеспечивающие хорошую производительность, могут привести к снижению производительности при рассмотрении новых данных. Во-вторых, оптимизация параметров может оказаться невозможной в некоторых случаях из-за временной сложности многих алгоритмов в сочетании с их обычно большим количеством параметров.В конечном итоге многие исследователи прибегают к применению алгоритмов классификатора или кластеризации с использованием параметров по умолчанию, предоставляемых программным обеспечением. Следовательно, требуются усилия для оценки и сравнения производительности алгоритмов кластеризации в ситуациях оптимизации и по умолчанию. Ниже мы рассмотрим некоторые представительные примеры алгоритмов, применяемых в литературе [37, 41].
Алгоритмы кластеризации реализованы в нескольких языках программирования и пакетах. Во время разработки и внедрения таких кодов обычно вносятся изменения или оптимизации, ведущие к новым версиям исходных методов.Настоящая работа сосредоточена на сравнительном анализе нескольких алгоритмов кластеризации, имеющихся в популярных пакетах, доступных на языке программирования R [42]. Этот выбор был мотивирован популярностью языка R в области интеллектуального анализа данных, а также благодаря хорошо зарекомендовавшим себя пакетам кластеризации, которые он содержит. Это исследование предназначено для помощи исследователям, которые имеют навыки программирования на языке R, но не имеют большого опыта кластеризации данных.
Алгоритмы оцениваются в трех различных ситуациях.Во-первых, мы рассматриваем их производительность при использовании параметров по умолчанию, предоставляемых пакетами. Затем мы рассматриваем изменение производительности, когда изменяются отдельные параметры алгоритмов, а для остальных сохраняются значения по умолчанию. Наконец, мы рассматриваем одновременное изменение всех параметров с помощью процедуры случайной выборки. Мы сравниваем результаты, полученные для последних двух ситуаций, с результатами, полученными с использованием параметров по умолчанию, таким образом, чтобы исследовать возможные улучшения производительности, которые могут быть достигнуты путем изменения алгоритмов.
Алгоритмы были оценены на 400 искусственных, нормально распределенных наборах данных, созданных с помощью надежной методологии, ранее описанной в [36]. Количество функций, количество классов, количество объектов для каждого класса и среднее расстояние между классами можно систематически изменять среди наборов данных.
Текст разделен следующим образом. Начнем с пересмотра некоторых основных подходов к сравнению алгоритмов кластеризации. Далее мы описываем рассматриваемые в анализе методы кластеризации, а также представляем пакеты R, реализующие такие методы.Представлены метод генерации данных и измерения производительности, используемые для сравнения алгоритмов, после чего представлены результаты производительности, полученные для параметров по умолчанию, для вариации одного параметра и для выборки случайных параметров.
Сопутствующие работы
Предыдущие подходы к сравнению производительности алгоритмов кластеризации можно разделить в зависимости от характера используемых наборов данных. В то время как в некоторых исследованиях используются реальные или искусственные данные, в других используются оба типа наборов данных для сравнения производительности нескольких методов кластеризации.
Сравнительный анализ с использованием реальных наборов данных представлен в нескольких работах [20, 21, 24, 25, 43, 44]. Ниже приводится краткий обзор некоторых из этих работ. В [43] авторы предлагают подход к оценке, основанный на принятии решений по множеству критериев в области анализа финансовых рисков по трем реальным наборам данных о кредитных рисках и рисках банкротства. Более конкретно, алгоритмы кластеризации оцениваются с точки зрения комбинации измерений кластеризации, которая включает в себя набор внешних и внутренних индексов достоверности.Их результаты показывают, что ни один алгоритм не может обеспечить наилучшую производительность по всем измерениям для любого набора данных, и по этой причине обязательно использовать более одного показателя производительности для оценки алгоритмов кластеризации.
В [21] был проведен сравнительный анализ методов кластеризации в контексте задачи проверки говорящего, не зависящей от текста, с использованием трех наборов данных документов. Были рассмотрены два подхода: алгоритмы кластеризации, ориентированные на минимизацию целевой функции на основе расстояния, и подход, основанный на гауссовых моделях.Сравнивались следующие алгоритмы: k-средние, случайный обмен, максимизация ожидания, иерархическая кластеризация, самоорганизованные карты (SOM) и нечеткие c-средние. Авторы обнаружили, что наиболее важным фактором успеха алгоритмов является порядок модели, который представляет собой количество рассматриваемых центроидных или гауссовских компонентов (для подходов, основанных на гауссовых моделях). В целом точность распознавания была аналогичной для алгоритмов кластеризации, направленных на минимизацию целевой функции на основе расстояния.Когда количество кластеров было небольшим, SOM и иерархические методы обеспечивали более низкую точность, чем другие методы. Наконец, сравнение вычислительной эффективности методов показало, что иерархический метод разделения является самым быстрым алгоритмом кластеризации в рассматриваемом наборе данных.
В [25] были изучены пять методов кластеризации: k-средних, многомерная гауссова смесь, иерархическая кластеризация, спектральный методы и методы ближайшего соседа. В экспериментах использовались четыре меры близости: коэффициент корреляции Пирсона и Спирмена, косинусное сходство и евклидово расстояние.Алгоритмы были оценены в контексте 35 данных экспрессии генов от Affymetrix или платформ чипов кДНК, с использованием скорректированного индекса rand для оценки производительности. Метод многомерной смеси Гаусса обеспечил наилучшую производительность при восстановлении фактического количества кластеров наборов данных. Аналогичную эффективность продемонстрировал метод k-средних. В этом же анализе иерархический метод привел к ограниченной производительности, в то время как спектральный метод показал, что он особенно чувствителен к применяемой мере приближения.
В [24] были проведены эксперименты по сравнению пяти различных типов алгоритмов кластеризации: CLICK, метод самоорганизованного отображения (SOM), k-means, иерархическая и динамическая кластеризация. Использовали наборы данных временных рядов экспрессии генов дрожжей Saccharomyces cerevisiae . Для сравнения различных алгоритмов была рассмотрена k-кратная процедура перекрестной проверки. Авторы обнаружили, что k-среднее, динамическая кластеризация и SOM имеют тенденцию давать высокую точность во всех экспериментах.С другой стороны, иерархическая кластеризация имела более ограниченную производительность при кластеризации больших наборов данных, что приводило к низкой точности в некоторых экспериментах.
Сравнительный анализ с использованием искусственных данных представлен в [45–47]. В [47] сравнивались два метода кластеризации подпространств: MAFIA (адаптивные сетки для кластеризации массивов данных) [48] и FINDIT (быстрый и интеллектуальный алгоритм кластеризации подпространств, использующий голосование по измерениям) [49]. Искусственные данные, смоделированные в соответствии с нормальным распределением, позволяли контролировать количество измерений и экземпляров.Методы оценивались с точки зрения масштабируемости и точности. В первом случае время работы обоих алгоритмов сравнивалось для разного количества экземпляров и функций. Кроме того, авторы оценили способность методов находить адекватные подпространства для каждого кластера. Они обнаружили, что MAFIA обнаружила все соответствующие кластеры, но в большинстве случаев не учитывалось одно важное измерение. И наоборот, метод FINDIT лучше справляется с задачей определения наиболее релевантных параметров.Было обнаружено, что оба алгоритма линейно масштабируются в зависимости от количества экземпляров, однако MAFIA превзошла FINDIT в большинстве тестов.
Другой распространенный подход к сравнению алгоритмов кластеризации рассматривает использование смеси реальных и искусственных данных (например, [23, 26–28, 50]). В [28] оценивалась эффективность k-средних, одинарного связывания и моделирования отжига (SA) с учетом различных разделов, полученных с помощью индексов валидации. Авторы использовали два набора данных реального мира, полученные из [51], и три набора искусственных данных (с двумя измерениями и 10 кластерами).Авторы предложили новый индекс проверки, названный индексом I , который измеряет расстояние, основанное на максимальном расстоянии между кластерами, и компактность, основанную на сумме расстояний между объектами и их соответствующими центроидами. Они обнаружили, что такой индекс является наиболее надежным среди других рассматриваемых индексов, достигая максимального значения при правильном выборе количества кластеров.
Систематическая количественная оценка четырех методов кластеризации на основе графов была проведена в [27].Сравниваемые методы были: кластеризация Маркова (MCL), кластеризация с ограниченным поиском по соседству (RNSC), суперпарамагнитная кластеризация (SPC) и обнаружение молекулярных комплексов (MCODE). Для сравнения использовались шесть наборов данных, моделирующих белковые взаимодействия в Saccharomyces cerevisiae и 84 случайных графиках. Для каждого алгоритма надежность методов измерялась двояко: изменение производительности количественно оценивалось с точки зрения изменений (i) параметров методов и (ii) свойств набора данных.В последнем случае соединения были включены и удалены, чтобы отразить неопределенность во взаимосвязи между белками. Метод кластеризации с ограниченным поиском по соседству оказался особенно устойчивым к изменениям в выборе параметров метода, тогда как другие алгоритмы оказались более устойчивыми к изменениям набора данных. В [52] авторы сообщают о кратком сравнении алгоритмов кластеризации с использованием набора фундаментальных задач кластеризации (FPC) в качестве набора данных. FPC содержит искусственные и реальные наборы данных для тестирования алгоритмов кластеризации.Каждый набор данных представляет собой конкретную задачу, с которой должен справиться алгоритм кластеризации, например, в наборах данных Hepta и LSum кластеры могут быть разделены линейной границей решения, но иметь разные плотности и дисперсии. С другой стороны, наборы данных ChainLink и Atom не могут быть разделены линейными границами принятия решений. Точно так же целевой набор данных содержит выбросы. Более низкая производительность была получена с помощью алгоритма кластеризации с одной связью для наборов данных Tetra, EngyTime, Twodiamonds и Wingnut.Хотя наборы данных довольно универсальны, невозможно контролировать и оценивать, как некоторые из их характеристик, такие как размеры или количество объектов, влияют на точность кластеризации.
Методы кластеризации
В литературе предложено много различных типов методов кластеризации [53–56]. Несмотря на такое разнообразие, некоторые методы используются чаще [57]. Кроме того, многие из обычно используемых методов определены в терминах аналогичных предположений о данных (например,g., k-means и k-medoids) или рассматривать аналогичные математические концепции (например, матрицы сходства для спектральной или графической кластеризации) и, следовательно, должны обеспечивать аналогичную производительность в типичных сценариях использования. Поэтому ниже мы рассмотрим выбор алгоритмов кластеризации из разных семейств методов. Было предложено несколько таксономий для организации множества различных типов алгоритмов кластеризации в семейства [29, 58]. В то время как одни таксономии классифицируют алгоритмы на основе их целевых функций [58], другие нацелены на конкретные структуры, желательные для полученных кластеров (например,г. иерархическая) [29]. Здесь мы рассматриваем алгоритмы, указанные в таблице 1, как примеры категорий, указанных в этой же таблице. Алгоритмы представляют собой некоторые из основных типов методов, описанных в литературе. Обратите внимание, что некоторые алгоритмы принадлежат к одному семейству, но в этих случаях они обладают заметными различиями в своих приложениях (например, обработка очень больших наборов данных с помощью clara). Краткое описание параметров каждого рассматриваемого алгоритма приведено в файле S1 дополнительного материала.
Таблица 1. Методы кластеризации, рассмотренные в нашем анализе, и соответствующие библиотеки и функции в R, использующие эти методы.
В первом столбце показаны названия алгоритмов, используемых в тексте. Во втором столбце указана категория алгоритмов. Третий и четвертый столбцы содержат, соответственно, имя функции и R-библиотеку каждого алгоритма.
https://doi.org/10.1371/journal.pone.0210236.t001
Что касается секционных подходов, исследователи широко использовали алгоритм k-средних [68] [57].Этот метод требует в качестве входных параметров количество групп ( k ) и метрику расстояния. Первоначально каждая точка данных связана с одним из кластеров k в соответствии с их расстоянием до центроидов (центров кластеров) каждого кластера. Пример показан на рис. 1 (а), где черные точки соответствуют центроидам, а остальные точки имеют тот же цвет, если центроид, ближайший к ним, такой же. Затем вычисляются новые центроиды, и классификация точек данных повторяется для новых центроидов, как показано на рис. 1 (b), где серые точки указывают положение центроидов в предыдущей итерации.Процесс повторяется до тех пор, пока на каждом новом шаге не будет наблюдаться никаких значительных изменений положения центроидов, как показано на рис. 1 (c) и 1 (d).
Рис. 1. Иллюстрация метода кластеризации k-средних.
Каждый график показывает раздел, полученный после определенных итераций алгоритма. Центроиды кластеров показаны черным маркером. Точки окрашены в соответствии с назначенными им кластерами. Серые маркеры указывают положение центроидов в предыдущей итерации.Набор данных содержит 2 кластера, но в алгоритме было использовано k = 4 начальных числа.
https://doi.org/10.1371/journal.pone.0210236.g001
Установка априори количества кластеров является основным ограничением алгоритма k-средних. Это так, потому что окончательная классификация может сильно зависеть от выбора числа центроидов [68]. Кроме того, k-среднее особенно не рекомендуется в случаях, когда кластеры не показывают выпуклого распределения или имеют очень разные размеры [59, 60].Более того, алгоритм k-средних чувствителен к начальному выбору начального числа [41]. Учитывая эти ограничения, было предложено множество модификаций этого алгоритма [61–63], такие как k-medoid [64] и k-means ++ [65]. Тем не менее, этот алгоритм, помимо низкой вычислительной стоимости, может обеспечить хорошие результаты во многих практических ситуациях, таких как обнаружение аномалий [66] и сегментация данных [67]. Подпрограмма R, используемая для кластеризации k-средних, была k-means из пакета stats , который содержит реализацию алгоритмов, предложенных Маккуином [68], Хартиганом и Вонгом [69].Алгоритм Хартигана и Вонга используется пакетом stats при установке для параметров значений по умолчанию, в то время как алгоритм, предложенный Маккуином, используется для всех остальных случаев. Другой интересный пример алгоритмов секционированной кластеризации — это кластеризация для больших приложений (clara) [70]. Этот метод учитывает несколько фиксированных выборок набора данных, чтобы минимизировать смещение выборки, и, следовательно, выбирает лучшие медоиды среди выбранных выборок, где медоид определяется как объект i , для которого среднее несхожесть со всеми другими объектами в его кластер минимален.Этот метод имеет тенденцию быть эффективным для больших объемов данных, поскольку он не исследует всю окрестность точек данных [71], хотя было обнаружено, что качество результатов сильно зависит от количества объектов в выборке данных [62 ]. Алгоритм clara, использованный в нашем анализе, был предоставлен функцией clara , содержащейся в пакете cluster . Эта функция реализует метод, разработанный Кауфманом и Руссеу [70].
Точки упорядочения для идентификации структуры кластеризации (ОПТИКА) [72, 73] — это упорядочение кластеров на основе плотности, основанное на концепции максимальной достижимости по плотности [72].Алгоритм начинается с точки данных и расширяет ее окрестность, используя аналогичную процедуру, что и в алгоритме dbscan [74], с той разницей, что окрестность сначала расширяется до точек с низким базовым расстоянием. Расстояние до центра объекта p определяется как м -ое наименьшее расстояние между p и объектами в его ϵ -сокрестности (т. Е. Объекты, расстояние до которых меньше или равно ϵ от p ), где m — параметр алгоритма, указывающий наименьшее количество точек, которые могут образовать кластер.Алгоритм оптики может обнаруживать кластеры с большими вариациями плотности и неправильной формы. Для кластеризации оптики использовалась процедура R optics из пакета dbscan . Эта функция учитывает исходный алгоритм, разработанный Ankerst et al. [72]. Иерархическая структура кластеризации на основе вывода оптического алгоритма может быть построена с использованием функции extractXi из пакета dbscan . Отметим, что функция extractDBSCAN из того же пакета обеспечивает кластеризацию из упорядочения оптики, аналогичную той, которую генерирует алгоритм dbscan.
Методы кластеризации, учитывающие связь между точками данных, традиционно известные как иерархические методы, можно разделить на две группы: агломеративные и разделяющие [59]. В алгоритме агломеративной иерархической кластеризации изначально каждый объект принадлежит соответствующему индивидуальному кластеру. Затем, после последовательных итераций, группы объединяются до тех пор, пока не будут достигнуты условия остановки. С другой стороны, метод разделяющей иерархической кластеризации начинается со всех объектов в одном кластере, и после последовательных итераций объекты разделяются на кластеры.На языке R есть два основных пакета, которые предоставляют процедуры для выполнения иерархической кластеризации, это stats и cluster . Здесь мы рассматриваем процедуру agnes из пакета cluster , которая реализует алгоритм, предложенный Кауфманом и Руссеу [70]. Четыре хорошо известных критерия связи доступны в agnes , а именно: одиночная связь, полная связь, метод Уорда и средневзвешенная связь [75].
Методы, основанные на моделях, можно рассматривать как общую основу для оценки максимального правдоподобия параметров базового распределения для данного набора данных.Хорошо известным примером методов, основанных на модели, является алгоритм максимизации ожидания (EM). Чаще всего считается, что данные из каждого класса можно моделировать многомерными нормальными распределениями, и, следовательно, распределение, наблюдаемое для всех данных, можно рассматривать как смесь таких нормальных распределений. Затем применяется подход максимального правдоподобия для нахождения наиболее вероятных параметров нормальных распределений каждого класса. EM-подход для кластеризации особенно подходит, когда набор данных неполный [76, 77].С другой стороны, кластеры, полученные методом, могут сильно зависеть от начальных условий [54]. Кроме того, алгоритм может не находить очень маленькие кластеры [29, 78]. На языке R пакет mclust [79, 80]. предоставляет итерационные методы EM (ожидания-максимизации) для оценки максимального правдоподобия с использованием параметризованных моделей гауссовской смеси. Функции estep и mstep реализуют отдельные шаги итерации EM. Связанный алгоритм, который также анализируется в текущем исследовании, — это hcmodel, который можно найти в функции hc пакета mclust .Алгоритм hcmodel, который также основан на гауссовых смесях, был предложен Фрейли [81]. Алгоритм содержит много дополнительных шагов по сравнению с традиционными методами ЭМ, таких как процедура агломерации и корректировка параметров модели посредством выбора байесовского фактора с использованием аппроксимации BIC [82].
Другой класс методов, рассматриваемых в нашем анализе, — это спектральная кластеризация. Эти методы возникли как альтернатива традиционным подходам кластеризации, которые не могли определять нелинейные дискриминантные гиперповерхности [83].Основное преимущество спектральных методов заключается в определении структуры смежности из исходного набора данных, что позволяет избежать наложения префикса формы для кластеров [84]. Первым шагом метода является построение матрицы сродства, где значение в строке j и столбце k указывает на сходство между точками j и k . Эту матрицу можно рассматривать как взвешенное графическое представление данных. Затем собственные значения и собственные векторы матрицы используются для разделения данных в соответствии с заданным критерием.Можно использовать множество различных типов матриц подобия, популярным выбором является матрица Лапласа [85]. Спектральные методы включают потенциально сложный процесс вычисления собственных векторов матрицы подобия [54]. Функция specc из пакета kernlab R реализует алгоритм Джордана и Вейсса [86], который использует функцию ядра для вычисления матрицы сродства из данных. Функция определяется как A ij = exp (- || x i — x j || 2 /2 σ 2 ) , где x i и x j — это точки для кластеризации в подмножества k , а σ 2 контролирует, насколько быстро матрица сродства A ij падает с расстоянием между x i и x j .Недавнее обсуждение взаимосвязи между спектральным алгоритмом и алгоритмом k-средних можно найти в [87]. Взвешенное ядро kmeans является обобщением метода kmeans. Его можно использовать для локальной оптимизации целей разделения графа на k непересекающихся разделов или кластеров. Обычно эта задача выполняется некоторым спектральным алгоритмом с использованием собственных векторов для определения разбиений. Однако, в зависимости от размера набора данных, вычисление большого количества собственных векторов может стать дорогостоящим в вычислительном отношении.Авторы показывают, что алгоритм взвешенного ядра k-средних может использоваться для оптимизации ряда задач разбиения графа.
В последние годы эффективная обработка данных большой размерности приобрела первостепенное значение, и по этой причине эта функция была желательной при выборе наиболее подходящего метода для получения точных разделов. Для работы с данными большой размерности была предложена кластеризация подпространств [49]. Этот метод работает, учитывая сходство между объектами в отношении различных подмножеств атрибутов [88].Мотивация для этого заключается в том, что разные подмножества атрибутов могут определять отдельные разделения между данными. Следовательно, алгоритм может идентифицировать кластеры, которые существуют в нескольких, возможно, перекрывающихся подпространствах [49]. Подпространственные алгоритмы можно разделить на четыре основных семейства [89], а именно: решетчатые, статистические, аппроксимационные и гибридные. Функция hddc из пакета HDclassif реализует метод кластеризации подпространств Бувейрона [90] на языке R.Алгоритм основан на статистических моделях с предположением, что все атрибуты могут иметь отношение к кластеризации [91]. Некоторые параметры алгоритма, такие как количество используемых кластеров или модели, оцениваются с помощью процедуры EM.
До сих пор мы обсуждали применение алгоритмов кластеризации для статических данных. Тем не менее, при анализе данных важно учитывать, являются ли данные динамическими или статическими. Динамические данные, в отличие от статических, со временем претерпевают изменения.Некоторые виды данных, такие как сетевые пакеты, полученные маршрутизатором, и потоки транзакций по кредитным картам, являются временными по своей природе и известны как поток данных . Другим примером динамических данных являются временные ряды, поскольку их значения меняются со временем [92]. Динамические данные обычно включают в себя большое количество функций, а количество объектов потенциально неограниченно [59]. Это требует применения новых подходов для быстрой обработки всего объема непрерывно поступающих данных [93], обнаружения новых образующихся кластеров и выявления выбросов [94].
Материалы и методы
Искусственные наборы данных
Для правильного сравнения алгоритмов кластеризации требуется надежный искусственный метод генерации данных для создания различных наборов данных. Для такой задачи мы применяем методологию, основанную на предыдущей работе Hirschberger et al. [35]. Процедуру можно использовать для создания нормально распределенных выборок, характеризующихся признаками F и разделенных на классы C . Кроме того, этот метод может управлять распределением дисперсии и корреляции между функциями для каждого класса.Искусственный набор данных также можно сгенерировать, варьируя количество объектов в классе N e и ожидаемое разделение α между классами.
Основная трудность при создании наборов данных с вышеупомянутыми свойствами — это определение правильной ковариационной матрицы R для рассматриваемых объектов. Действительная ковариационная матрица должна быть положительно полуопределенной [95], что трудно обеспечить. Однако для данной матрицы матрица R = GG T гарантированно будет положительно полуопределенной [95].Таким образом, любая случайная матрица G может определять действительную соответствующую ковариационную матрицу. Как следствие, могут быть наложены дополнительные ограничения на матрицу G для создания наборов данных с требуемыми свойствами. Hirschberger et al. [35] разработали надежный подход для создания такой матрицы с учетом первых двух статистических моментов распределения ковариации набора искусственных признаков F . Результирующая ковариационная матрица содержит дисперсии и ковариации, полученные из такого распределения.Здесь мы рассматриваем нормальное распределение для представления элементов R .
Для каждого класса i в наборе данных создается ковариационная матрица R i размером F × F , и эта матрица используется для создания объектов N e объектов для занятий. Это означает, что пары функций могут иметь четкую корреляцию для каждого сгенерированного класса. Затем сгенерированные значения класса делятся на α и преобразуются в s i , где s i — случайная величина, описываемая равномерным случайным распределением, определенным в интервале [−1 , 1].Параметр α связан с ожидаемыми расстояниями между классами. Такие расстояния могут по-разному влиять на кластеризацию в зависимости от количества объектов и функций, используемых в наборе данных. Функции в сгенерированных данных имеют многомерное нормальное распределение. Кроме того, ковариация между функциями также имеет нормальное распределение. Обратите внимание, что такая процедура для создания искусственных наборов данных ранее использовалась в [36].
На рис. 2 мы показываем несколько примеров искусственно сгенерированных данных.Для наглядности все рассмотренные случаи содержат F = 2 признака. Параметры, используемые для каждого случая, описаны в подписи к рисунку. Обратите внимание, что методология может генерировать различные конфигурации наборов данных, включая вариации корреляции функций для каждого класса.
Рис. 2. Примеры искусственных наборов данных, созданных с помощью методологии.
Параметры, используемые для каждого случая: (a) C = 2, Ne = 100 и α = 3.3. (б) C = 2, Ne = 100 и α = 2.3. (в) C = 10, Ne = 50 и α = 4.3. (г) C = 10, Ne = 50 и α = 6,3. Обратите внимание, что каждый класс может представлять очень разные свойства из-за различий в корреляции между их функциями.
https://doi.org/10.1371/journal.pone.0210236.g002
В этом исследовании мы рассмотрели следующие значения параметров искусственного набора данных:
- Количество классов ( C ): сгенерированные наборы данных делятся на классы C = {2, 10, 50}.
- Количество элементов ( F ): Количество элементов, характеризующих объекты, составляет F = {2, 5, 10, 50, 200}.
- Количество объектов на класс ( N e ): мы рассмотрели Ne = {5, 50, 100, 500, 5000} объектов на класс. В наших экспериментах в заданном сгенерированном наборе данных количество экземпляров для каждого класса постоянно.
- Параметр смешивания ( α ): Этот параметр имеет нетривиальную зависимость от количества классов и функций.Поэтому для каждого набора данных значение этого параметра было настроено так, чтобы ни один алгоритм не достиг точности 0% или 100%.
Мы называем наборы данных, содержащие 2, 10, 50 и 200 функций, DB2F, DB10F, DB50F, DB200F соответственно. Такие наборы данных состоят из всего рассматриваемого количества классов, C = {2, 10, 50}, и 50 элементов для каждого класса (т.е. Ne = 50). В некоторых случаях мы также указываем количество классов, рассматриваемых для набора данных. Например, набор данных DB2C10F содержит 2 класса, 10 функций и 50 элементов на класс.
Для каждого случая мы рассматриваем 10 реализаций набора данных. Таким образом, всего было сгенерировано 400 наборов данных.
Оценка производительности алгоритмов кластеризации
Оценка качества сгенерированных разделов — одна из важнейших задач кластерного анализа [30]. Индексы, используемые для измерения качества раздела, можно разделить на два класса: внутренние и внешние индексы. Индексы внутренней проверки основаны на информации, присущей данным, и оценивают качество структуры кластеризации без внешней информации.Когда правильный раздел недоступен, можно оценить качество раздела, измерив, насколько тесно каждый экземпляр связан с кластером и насколько хорошо кластер отделен от других кластеров. В основном они используются для выбора оптимального алгоритма кластеризации, который будет применяться к конкретному набору данных [96]. С другой стороны, индексы внешней проверки измеряют сходство между выходными данными алгоритма кластеризации и правильным разбиением набора данных. Индекс Жаккара, Фаулкса-Маллоуса и скорректированный индекс ранда относятся к одной и той же категории подсчета пар, что делает их тесно связанными.Некоторые различия включают тот факт, что они могут демонстрировать смещение относительно количества кластеров или распределения размеров классов в разделе. Нормализация помогает предотвратить этот нежелательный эффект. В [97] авторы обсуждают несколько типов систематической ошибки, которая может повлиять на индексы валидности внешнего кластера. В общей сложности 26 индексов валидности внешних кластеров на основе подсчета пар использовались для выявления систематической ошибки, вызванной количеством кластеров. Было показано, что индексы Fowlkes Mallows и Jaccard монотонно уменьшаются по мере увеличения количества кластеров, отдавая предпочтение разделам с меньшим количеством кластеров, в то время как скорректированный индекс Rand, как правило, безразличен к количеству кластеров.
Здесь мы принимаем самые традиционные внешние индексы, а именно: индекс Жаккара (J) [31], скорректированный индекс Рэнда (ARI) [32], индекс Маллоуз Фаулкса (FM) [33] и нормализованная взаимная информация (NMI) [ 34]. Чтобы определить внешний индекс кластера, мы рассмотрим следующие концепции. Пусть U = { u 1 , u 2 … u R } представляет исходный раздел набора данных, где u i обозначает подмножество объекты, связанные с кластером i .Аналогично, пусть V = { v 1 , v 2 … v C } представляет раздел, найденный кластерным алгоритмом. Обозначим как a количество пар объектов, помещенных в одну группу как в U , так и в V . Математически a может быть вычислено следующим образом: (1) где n ij — количество объектов, принадлежащих обоим подмножествам u i и v j .
Пусть b указывает количество пар объектов, принадлежащих одной группе в U , но разным группам в V , т.е. (2) где n i . = ∑ j n ij . Пусть c будет количеством пар объектов, принадлежащих к разным группам в U и к той же группе в V , что можно записать как (3) где n . j = ∑ i n ij .
Затем можно определить индекс Жаккарда ( J ), скорректированный индекс Рэнда (ARI) и индекс Маллоуз Фаулкса (FM) на основе a , b , c : (4) (5) (6)
Мы также рассматриваем нормализованную взаимную информацию (NMI) как показатель качества, потому что она количественно определяет взаимную зависимость между двумя случайными величинами на основе хорошо установленных концепций теории информации [98].Мера NMI определяется как [99] (7) где C — случайная величина, обозначающая кластерные присвоения точек, а T — случайная величина, обозначающая базовые метки классов на точках. I ( C , T ) = H ( C ) — H ( C | T ) — это взаимная информация между случайными величинами C и T . H ( C ) — энтропия Шеннона для C . H ( C | T ) — это условная энтропия C при T .
Обратите внимание, что когда два набора этикеток имеют полное взаимно однозначное соответствие, все показатели качества равны единице.
Предыдущие работы показали, что не существует единого внутреннего индекса проверки кластера, который превосходил бы другие индексы [100, 101]. В [101] авторы сравнивают набор индексов проверки внутреннего кластера во многих различных сценариях, указывая на то, что индекс Silhouette давал лучшие результаты в большинстве случаев.
Индекс проверки Данна количественно определяет не только степень компактности кластеров, но и степень разделения между отдельными кластерами. Таким образом, цель состоит в том, чтобы максимизировать расстояние между кластерами при минимальном расстоянии внутри кластера, где c i представляет i-й кластер раздела. Индекс рассчитывается как (8) где dist ( c i , c j ) — минимальное расстояние между кластерами c i и c j , иВысокое значение этого показателя указывает на компактный и хорошо разделенный кластер.
Силуэтный индекс (SI) вычисляет ширину каждой точки в зависимости от ее принадлежности внутри кластера. (9) где n — общее количество точек, a i — среднее расстояние между точкой i и всеми другими точками в собственном кластере, а b i — минимум средние различия между и и точками в других кластерах.Интервал значений индекса силуэта составляет −1 ≤ SI ≤ 1. Оптимальным считается разбиение с наибольшим SI.
Результаты и обсуждение
Точность каждого рассмотренного алгоритма кластеризации оценивалась с использованием трех методик. В первой методологии мы рассматриваем параметры по умолчанию для алгоритмов, предоставляемых пакетом R. Причина измерения производительности с использованием параметров по умолчанию заключается в том, чтобы рассмотреть случай, когда исследователь применяет классификатор к набору данных без какой-либо корректировки параметров.Это распространенный сценарий, когда исследователь не является экспертом в области машинного обучения. Во второй методике мы количественно оцениваем влияние параметров алгоритмов на точность. Это делается путем изменения одного параметра алгоритма, сохраняя значения остальных параметров по умолчанию. Третья методика заключается в анализе производительности путем случайного изменения всех параметров классификатора. Эта процедура позволяет количественно оценить определенные свойства, такие как максимальная достигаемая точность и чувствительность алгоритма к изменению параметров.
Производительность при использовании параметров по умолчанию
В этом эксперименте мы оценили производительность классификаторов для всех наборов данных, описанных в Разделе Искусственные наборы данных . Все неконтролируемые алгоритмы были установлены с настройкой параметров по умолчанию. Для каждого алгоритма мы делим результаты в соответствии с количеством функций, содержащихся в наборе данных. Другими словами, для заданного количества функций, F , мы использовали наборы данных с классами C = {2, 10, 50, 200} и N e = {5, 50, 100 } объекты для каждого класса.Таким образом, результаты производительности, полученные для каждого F , соответствуют производительности, усредненной по разному количеству классов и объектов в классе. Следует отметить, что алгоритм, основанный на подпространствах, не может быть применен к наборам данных, содержащим 2 объекта, и поэтому его точность не была оценена количественно для таких наборов данных.
На рис. 3 показаны полученные значения для четырех рассматриваемых показателей производительности. Результаты показывают, что все показатели производительности дают аналогичные результаты. Кроме того, на иерархический метод, похоже, сильно влияет количество функций в наборе данных.Фактически, при использовании 50 и 200 признаков иерархический метод давал меньшую точность. Методы k-средних, спектральный, оптический и dbscan выигрывают от увеличения количества функций. Интересно, что hcmodel имеет лучшую производительность в наборах данных, содержащих 10 функций, чем в наборах данных, содержащих 2, 50 и 200 функций, что предполагает оптимальную производительность для этого алгоритма для наборов данных, содержащих около 10 функций. Также ясно, что для двух функций производительность алгоритмов, как правило, схожа, за исключением методов optics и dbscan.С другой стороны, большее количество функций приводит к заметным различиям в производительности. В частности, для 200 признаков спектральный алгоритм дает лучшие результаты среди всех классификаторов.
Рис. 3. Средняя производительность семи рассмотренных алгоритмов кластеризации в зависимости от количества функций в наборе данных.
Для оценки использовались все искусственные наборы данных. Средние значения рассчитывались отдельно для наборов данных, содержащих 2, 10 и 50 объектов. Рассматриваемые индексы производительности: (а) скорректированный Рэнд, (б) Жаккар, (в) нормализованная взаимная информация и (г) Маллоуз Фаулкса.
https://doi.org/10.1371/journal.pone.0210236.g003
Мы используем тест Краскела-Уоллиса [102], непараметрический тест, чтобы исследовать статистические различия в производительности при рассмотрении определенного количества функций в методах кластеризации. . Сначала мы проверяем, значительна ли разница в производительности для двух функций. В этом случае тест Крускала-Уоллиса возвращает значение p, равное p = 6,48 × 10 −7 , с расстоянием хи-квадрат × 2 = 41.50. Следовательно, разница в производительности статистически значима при рассмотрении всех алгоритмов. Для наборов данных, содержащих 10 объектов, значение p p ( = 1,53 × 10 −8 ) возвращается тестом Краскала-Уоллиса с расстоянием хи-квадрат × ( 2 = 52,20). Для 50 функций тест возвращает значение p p ( = 1,56 × 10 −6 ) с расстоянием хи-квадрат × ( 2 = 41,67). Для 200 функций тест возвращает значение p p = 2.49 × 10 −6 , с расстоянием хи-квадрат × 2 = 40,58). Таким образом, нулевая гипотеза теста Краскела – Уоллиса отклоняется. Это означает, что алгоритмы действительно имеют значительные различия в производительности для 2, 10, 50 и 200 функций, как показано на рис. 3.
Чтобы проверить влияние количества объектов, используемых для классификации, мы также вычислили среднюю точность для наборов данных, разделенных в соответствии с количеством объектов N e .Результат показан на рис. 4. Мы видим, что влияние, которое изменение N e оказывает на точность, зависит от алгоритма. Удивительно, но иерархические методы, методы k-средних и клара имеют более низкую точность при использовании большего количества данных. Результат показывает, что эти алгоритмы имеют тенденцию быть менее устойчивыми по отношению к большему перекрытию между кластерами из-за увеличения количества объектов. Мы также заметили, что более крупный N e увеличивает производительность hcmodel, оптики и алгоритмов dbscan.Этот результат согласуется с [90].
Рис. 4. Средняя производительность семи рассмотренных алгоритмов кластеризации в зависимости от количества объектов на класс в наборе данных.
Для оценки использовались все искусственные наборы данных. Средние значения рассчитывались отдельно для наборов данных, содержащих 5, 50 и 100 объектов на класс. Рассматриваемые индексы производительности: (а) скорректированный Рэнд, (б) Жаккар, (в) нормализованная взаимная информация и (г) Маллоуз Фаулкса.
https: // doi.org / 10.1371 / journal.pone.0210236.g004
В большинстве алгоритмов кластеризации размер данных влияет на качество кластеризации. Чтобы количественно оценить этот эффект, мы рассмотрели сценарий, в котором данные имеют большое количество экземпляров. Были созданы наборы данных с F = 5, C = 10 и Ne = {5, 50, 500, 5000} экземпляров для каждого класса. Этот набор данных будет обозначаться как DB10C5F. На рис. 5 мы можем наблюдать, что подпространственные и спектральные методы приводят к повышению точности при увеличении количества экземпляров.С другой стороны, размер набора данных не влияет на точность алгоритмов kmeans, clara, hcmodel и EM. Для спектральных, иерархических и hc-модельных алгоритмов точность не могла быть рассчитана при использовании 5000 экземпляров на класс из-за объема памяти, используемой этими методами. Например, в случае метода спектрального алгоритма требуется большая вычислительная мощность для вычисления и сохранения матрицы ядра при выполнении алгоритма. Когда размер набора данных слишком мал, мы видим, что алгоритм подпространства дает низкую точность.
Рис. 5. Производительность алгоритмов, когда количество элементов по классам соответствует Ne = 5, 50, 500, 5000.
Графики соответствуют индексам ARI, Jaccard и FM, усредненным для всех наборов данных, содержащих 10 классов и 5 функций (DB10C5F).
https://doi.org/10.1371/journal.pone.0210236.g005
Также интересно проверить производительность алгоритмов кластеризации при установке различных значений для ожидаемого количества классов K в наборе данных.Такое значение обычно заранее не известно в реальных наборах данных. Например, можно было бы ожидать, что данные будут содержать 10 классов, и, как следствие, установить в алгоритме K = 10, но на самом деле объекты могут быть лучше размещены в 12 классах. Точный алгоритм по-прежнему должен давать разумные результаты, даже если предполагается неправильное количество классов. Таким образом, мы изменили K для каждого алгоритма и проверили полученное изменение точности. Обратите внимание, что методы optics и dbscan не рассматривались в этом анализе, поскольку они не имеют параметра для установки количества классов.Для упрощения анализа мы рассматривали только наборы данных, состоящие из объектов, описываемых 10 функциями и разделенных на 10 классов (DB10C10F). Результаты показаны на рисунке 6. Верхние цифры соответствуют средним индексам ARI и Jaccard, рассчитанным для DB10C10F, а индексы Silhoute и Dunn показаны внизу рисунка. Результаты показывают, что установка K <10 приводит к худшей производительности, чем полученная для случаев, когда K > 10, что предполагает, что небольшое завышение количества классов меньше влияет на производительность.Следовательно, хорошая стратегия выбора K , кажется, заключается в установке значений, которые немного превышают количество ожидаемых классов. Интересное поведение наблюдается для иерархической кластеризации. Точность повышается по мере увеличения количества ожидаемых классов. Такое поведение происходит из-за значения по умолчанию для параметра method , которое установлено как «среднее». «Среднее» значение означает, что для агломерации точек используется невзвешенный метод парных групп со средним арифметическим (UPGMA).UPGMA — это среднее значение различий между точками в одном кластере и точками в другом кластере. Умеренная производительность UPGMA в восстановлении исходных групп, даже с высокой дифференциацией подгрупп, вероятно, является следствием того факта, что UPGMA имеет тенденцию приводить к более несбалансированным кластерам, то есть большинство объектов назначается нескольким кластерам, в то время как многие другие кластеры содержат только один или два объекта.
Рис 6. Производительность алгоритмов при изменении ожидаемого количества кластеров K в наборе данных.
Верхние графики соответствуют индексам ARI и Jaccard, усредненным для всех наборов данных, содержащих 10 классов и 10 функций (DB10C10F). Нижние графики соответствуют индексам Silhouette и Dunn для того же набора данных. Красная линия указывает фактическое количество кластеров в наборе данных.
https://doi.org/10.1371/journal.pone.0210236.g006
Индексы внешней проверки показывают, что большинство алгоритмов кластеризации правильно идентифицируют 10 основных кластеров в наборе данных.Естественно, эти знания не будут доступны в реальном кластерном анализе. По этой причине мы также рассматриваем внутренние индексы проверки, которые обеспечивают обратную связь о качестве раздела. Были рассмотрены два внутренних индекса проверки: индекс Silhouette (определенный в диапазоне [-1,1]) и индекс Данна (определенный в диапазоне [0, ∞]). Эти индексы были применены к набору данных DB10C10F и DB10C2F при изменении ожидаемого количества кластеров K . Результаты представлены на рисунках 6 и 7.На рис. 6 видно, что результаты, полученные для разных алгоритмов, в основном схожи. Результаты для индекса Silhouette показывают высокую точность около k = 10. Индекс Данна показывает немного более низкую производительность, неверно оценивая правильное количество кластеров для иерархического алгоритма. На рис. 7 Силуэт и Данн демонстрируют аналогичное поведение.
Рис 7. Производительность алгоритмов при изменении ожидаемого количества кластеров K в наборе данных.
Верхние графики соответствуют индексам ARI и Jaccard, усредненным для всех наборов данных, содержащих 10 классов и 2 функции (DB10C2F).Нижние графики соответствуют индексам Silhouette и Dunn для того же набора данных. Красная линия указывает фактическое количество кластеров в наборе данных.
https://doi.org/10.1371/journal.pone.0210236.g007
Результаты, полученные для параметров по умолчанию, приведены в таблице 2. Таблица разделена на четыре части, каждая часть соответствует метрике производительности. Для каждого показателя производительности значение в строке i и столбце j таблицы представляет среднюю производительность метода в строке i за вычетом средней производительности метода в столбце j .В последнем столбце таблицы указана средняя производительность каждого алгоритма. Отметим, что средние значения были взяты по всем сгенерированным наборам данных.
Таблица 2. Средняя разница в точности, полученная при использовании алгоритмов кластеризации с их конфигурацией параметров по умолчанию.
В целом спектральный алгоритм обеспечивает наивысшую точность среди всех оцениваемых методов.
https://doi.org/10.1371/journal.pone.0210236.t002
Результаты, показанные в таблице 2, показывают, что спектральный алгоритм имеет тенденцию превосходить другие алгоритмы как минимум на 10%.С другой стороны, иерархический метод в большинстве рассмотренных случаев показал более низкую производительность. Другой интересный результат заключается в том, что k-means и clara обеспечивают одинаковую производительность при рассмотрении всех наборов данных. В свете результатов предпочтение может отдаваться спектральному методу, когда не проводится оптимизация значений параметров.
Одномерный анализ
Целью одномерного анализа является проверка того, насколько чувствительна точность алгоритмов кластеризации к изменению одного параметра.Кроме того, этот анализ также полезен для проверки того, может ли очень простая стратегия оптимизации привести к значительному повышению производительности. Для одномерного анализа мы рассмотрели базы данных DB2C2F (с α = 2,5), DB10C2F (с α = 4,3), DB2C10F (с α = 1,16), DB10C10F (с α = 1,75). , DB2C200F (с α = 0,87) и DB10C200F (с α = 1,09). Для каждого параметра мы варьировали его значения, сохраняя при этом другие параметры в их конфигурации по умолчанию.Эффект изменения значений одного параметра P был количественно оценен путем сравнения полученной точности Γ ( x ), когда параметр принимает значение x , и точности Γ def , достигнутой при конфигурации параметров по умолчанию. Улучшение производительности было количественно выражено с точки зрения среднего (〈 S 〉) и максимального значения (макс. S ), определяемого следующим образом: (10) (11) где n P — мощность всех возможных значений, принимаемых параметром P в наших экспериментах.Мы также измерили чувствительность изменения значений P , используя стандартное отклонение Δ S : (12)
В дополнение к вышеупомянутым величинам мы также измерили для каждого набора данных максимальную точность, полученную при изменении каждого отдельного параметра алгоритма. Затем мы вычисляем среднее значение максимальной точности 〈max Acc〉, полученное по всем рассматриваемым наборам данных. В таблице 3 мы показываем значения 〈 S 〉, max S , Δ S и 〈max Acc〉 для наборов данных, содержащих два объекта.При рассмотрении двухклассовой задачи (DB2C2F) значительное улучшение производительности (〈 S 〉 = 10,75% и 〈 S 〉 = 13,35%) наблюдалось при изменении параметра modelName , minPts и kpar соответственно ЭМ, оптике и спектральным методам. Во всех остальных случаях наблюдался лишь незначительный средний прирост производительности. Для задачи с 10 классами отметим, что неадекватное значение параметра метода иерархического алгоритма может привести к существенной потере точности (16.15% в среднем). Однако в большинстве случаев средняя разница в производительности была небольшой.
Таблица 3. Однопараметрический анализ, выполненный в DB2C2F и DB10C2F.
Этот анализ основан на производительности (измеренной с помощью индекса ARI), полученной при изменении одного параметра алгоритма кластеризации при сохранении других параметров в их конфигурации по умолчанию. 〈 S 〉, max S , Δ S связаны со средним значением, стандартным отклонением и максимальной разницей между характеристиками, полученными при изменении одного параметра, и характеристиками, полученными для значений параметров по умолчанию.Мы также измеряем 〈max Acc〉, среднее из лучших значений ARI, полученных при изменении каждого параметра, где среднее значение рассчитывается по всем рассматриваемым наборам данных.
https://doi.org/10.1371/journal.pone.0210236.t003
В таблице 4 мы показываем значения 〈 S 〉, max S , Δ S и 〈max Acc〉 для наборов данных. описывается 10 функциями. Для задачи двухклассовой кластеризации можно наблюдать умеренное улучшение для k-средних, иерархического и оптического алгоритма за счет изменения, соответственно, параметра nstart , метода и minPts .Значительное повышение точности наблюдалось при изменении параметра modelName метода ЭМ. Изменение модели modelName , используемой алгоритмом, привело в среднем к улучшению на 18,8%. Аналогичное поведение было получено, когда количество классов было установлено равным C = 10. Для 10 классов вариант метода в иерархическом алгоритме обеспечил среднее улучшение на 6,72%. Большое улучшение также наблюдалось при изменении параметра modelName алгоритма EM со средним улучшением 13.63%.
Таблица 4. Однопараметрический анализ, выполненный в DB2C10F и DB10C10F.
Этот анализ основан на производительности, полученной при изменении одного параметра при сохранении конфигурации остальных параметров по умолчанию. 〈 S 〉, max S , Δ S связаны со средним значением, стандартным отклонением и максимальной разницей между характеристиками, полученными при изменении одного параметра, и характеристиками, полученными для значений параметров по умолчанию.Мы также измеряем 〈max Acc〉, среднее из лучших значений ARI, полученных при изменении каждого параметра, где среднее значение рассчитывается по всем рассматриваемым наборам данных.
https://doi.org/10.1371/journal.pone.0210236.t004
В отличие от параметров, обсуждаемых до сих пор, изменение некоторых параметров играет второстепенную роль в различительной способности алгоритмов кластеризации. Это относится, например, к параметрам kernel и iter алгоритма спектральной кластеризации и параметру iter.max кластеризации kmeans. В некоторых случаях эффект одномерного изменения параметра приводил к снижению производительности. Например, изменение мин. Индивидов и моделей подпространственного алгоритма обеспечило среднюю потерю точности порядка 〈 S 〉 = 20%, в зависимости от набора данных. Аналогичное поведение наблюдается для метода dbscan, для которого изменение minPts приводит к средней потере точности 20.32%. Параметры metric и rngR алгоритма clara также привели к заметному снижению производительности.
В таблице 5 мы показываем значения 〈 S 〉, max S , Δ S и 〈max Acc〉 для наборов данных, описываемых 200 объектами. Для задачи кластеризации двух классов значительное улучшение производительности наблюдалось при изменении nstart в методе k-средних, метод в иерархическом алгоритме, modelName в методе hcmodel и modelName в методе EM .С другой стороны, при изменении метрики , мин. Лица и используют в методах clara, subspace и hcmodel соответственно, средняя потеря точности более 10% была подтверждена. Наибольшая потеря точности происходит с параметром minPts (49,47%) метода dbscan. Для задачи с 10 классами наблюдались аналогичные результаты, за исключением метода Клары, для которого любое изменение параметра приводило к большой потере точности.
Таблица 5.Однопараметрический анализ, выполненный в DB2C200F и DB10C200F.
Этот анализ основан на производительности, полученной при изменении одного параметра при сохранении конфигурации остальных параметров по умолчанию. 〈 S 〉, max S , Δ S связаны со средним значением, стандартным отклонением и максимальной разницей между характеристиками, полученными при изменении одного параметра, и характеристиками, полученными для значений параметров по умолчанию. Мы также измеряем 〈max Acc〉, среднее из лучших значений ARI, полученных при изменении каждого параметра.
https://doi.org/10.1371/journal.pone.0210236.t005
Многомерный анализ
Полный анализ производительности алгоритма кластеризации требует одновременного изменения всех его параметров. Тем не менее, такую задачу сложно выполнить на практике, учитывая большое количество комбинаций параметров, которые необходимо учитывать. Поэтому здесь мы рассматриваем случайное изменение параметров, направленное на получение выборки производительности каждого алгоритма для его полного многомерного пространства параметров.
Методология применяется следующим образом. Рассматривая одномерное изменение параметров, представленное в предыдущем разделе, мы определяем границы параметров, [ P min , P max ], где классификация либо больше не претерпевает значительных изменений, либо дает существенно меньшие производительность по сравнению со значением параметра по умолчанию. Такие границы определяют интервал, в котором параметр будет выбираться случайным образом. Чтобы сгенерировать значения для заданного набора параметров P (1) , P (2) ,…, P ( n ) алгоритма, мы произвольно выбираем каждый параметр P ( i ) в соответствии с равномерным распределением, заданным в интервале.Эта процедура генерирует наборы значений параметров, которые затем используются для оценки производительности алгоритмов. Для каждого алгоритма было сгенерировано 500 наборов параметров.
Эффективность алгоритмов для различных наборов параметров оценивалась в соответствии со следующей процедурой. Рассмотрим гистограмму значений ARI, полученных для случайной выборки параметров для алгоритма k-средних, показанную на рисунке 8. Красная пунктирная линия указывает значение ARI, полученное для параметров алгоритма по умолчанию.Светло-синяя заштрихованная область указывает конфигурации параметров, в которых производительность алгоритма улучшилась. Исходя из этого результата, мы рассчитали четыре основных показателя. Первое, которое мы называем p-значением, определяется как площадь синей области, деленная на общую площадь гистограммы, умноженную на 100, чтобы получить процентное значение. Значение p представляет процент конфигураций параметров, в которых производительность алгоритма улучшилась по сравнению с конфигурацией параметров по умолчанию.Вторая, третья и четвертая меры представлены средним значением 〈 R 〉, стандартным отклонением Δ R и максимальным значением max R относительной производительности для всех случаев, когда производительность улучшается (например, синяя заштрихованная область на рис. 8). Относительная производительность рассчитывается как разница в производительности между заданной реализацией значений параметров и параметрами по умолчанию. Среднее значение указывает на ожидаемое улучшение алгоритма случайного изменения параметров.Стандартное отклонение представляет стабильность такого улучшения, то есть степень уверенности в том, что производительность будет улучшена при выполнении такого случайного изменения. Максимальное значение указывает на наибольшее улучшение, полученное при рассмотрении случайных параметров. Мы также измерили среднее значение максимальной точности 〈max ARI〉, полученное для каждого набора данных при случайном выборе параметров. В файле S2 дополнительного материала мы показываем распределение значений ARI, полученных при случайной выборке параметров для всех рассмотренных в нашем анализе алгоритмов кластеризации.
В таблице 6 мы показываем производительность (ARI) алгоритмов для набора данных DB2C2F при применении вышеупомянутого случайного выбора параметров. Оптика и методы ЭМ — единственные алгоритмы, у которых значение p превышает 50%. Также высокий средний прирост производительности наблюдался для EM (22,1%) и иерархического (30,6%) методов. Умеренное улучшение наблюдалось для алгоритмов hcmodel, kmeans, спектрального, оптического и dbscan.
Таблица 6. Многопараметрический анализ, выполненный в наборе данных DB2C2F.
Значение p представляет вероятность того, что набор классификаторов со случайной конфигурацией параметров превосходит тот же набор классификаторов со своими параметрами по умолчанию. 〈 R 〉, Δ R и max R представляют собой среднее, стандартное отклонение и максимальное значение улучшения, полученного при рассмотрении случайных параметров. Столбец 〈max ARI〉 указывает среднее значение наилучшей точности, полученной для каждого набора данных.
https://doi.org/10.1371 / journal.pone.0210236.t006
Производительность алгоритмов для набора данных DB10C2F представлена в таблице 7. Высокое значение p было получено для оптики (96,6%), EM (76,5%) и k-средних ( 77,7%). Тем не менее, среднее улучшение производительности было относительно низким для большинства алгоритмов, за исключением метода оптики, который привел к среднему улучшению на 15,9%.
Таблица 7. Многопараметрический анализ, выполненный в наборе данных DB10C2F.
Значение p представляет вероятность того, что набор классификаторов со случайной конфигурацией параметров превосходит тот же набор классификаторов со своими параметрами по умолчанию.〈 R 〉, Δ R и max R представляют собой среднее, стандартное отклонение и максимальное значение улучшения, полученного при рассмотрении случайных параметров. Столбец 〈max ARI〉 указывает среднее значение наилучшей точности, полученной для каждого набора данных.
https://doi.org/10.1371/journal.pone.0210236.t007
Более заметные различия в производительности наблюдались для набора данных DB2C10F, результаты показаны в таблице 8. Алгоритмы EM, kmeans, иерархической и оптической кластеризации привели к p-значение больше 50%.В таких случаях, когда производительность была улучшена, средний прирост производительности составил соответственно 30,1%, 18,0%, 25,9% и 15,5%. Это означает, что случайное изменение параметров может представлять допустимый подход к улучшению этих алгоритмов. Фактически, за исключением clara и dbscan, все методы показывают значительное среднее улучшение производительности для этого набора данных. Результаты также показывают, что максимальная точность 100% может быть достигнута для алгоритмов EM и подпространственных алгоритмов.
Таблица 8.Многопараметрический анализ, выполненный в наборе данных DB2C10F.
Значение p представляет вероятность того, что набор классификаторов со случайной конфигурацией параметров превосходит тот же набор классификаторов со своими параметрами по умолчанию. 〈 R 〉, Δ R и max R представляют собой среднее, стандартное отклонение и максимальное значение улучшения, полученного при рассмотрении случайных параметров. Столбец 〈max ARI〉 указывает среднее значение наилучшей точности, полученной для каждого набора данных.
https://doi.org/10.1371/journal.pone.0210236.t008
В таблице 9 мы показываем производительность алгоритмов для набора данных DB10C10F. Значения p для EM, clara, k-means и оптики показывают, что случайный выбор параметров обычно улучшает производительность этих алгоритмов. Иерархический алгоритм может быть существенно улучшен за счет рассмотренного случайного выбора параметров. Это является следствием значения по умолчанию для параметра метода , которое, как обсуждалось в предыдущем разделе, не подходит для этого набора данных.
Таблица 9. Многопараметрический анализ, выполненный в наборе данных DB10C10F.
Значение p представляет вероятность того, что набор классификаторов со случайной конфигурацией параметров превосходит тот же набор классификаторов со своими параметрами по умолчанию. 〈 R 〉, Δ R и max R представляют собой среднее, стандартное отклонение и максимальное значение улучшения, полученного при рассмотрении случайных параметров. Столбец 〈max ARI〉 указывает среднее значение наилучшей точности, полученной для каждого набора данных.
https://doi.org/10.1371/journal.pone.0210236.t009
Производительность алгоритмов для набора данных DB2C200F представлена в таблице 10. Высокое значение p было получено для EM (65,1%) и k -средние (65,6%) алгоритмы. Средний прирост производительности в таких случаях составил 39,1% и 35,4% соответственно. С другой стороны, только примерно в 16% случаев методы Spectral и Subspace привели к улучшению ARI. Интересно, что случайное изменение параметров привело в среднем к значительному повышению производительности всех алгоритмов.
Таблица 10. Многопараметрический анализ, выполненный в наборе данных DB2C200F.
Значение p представляет вероятность того, что набор классификаторов со случайной конфигурацией параметров превосходит тот же набор классификаторов со своими параметрами по умолчанию. 〈 R 〉, Δ R и max R представляют собой среднее, стандартное отклонение и максимальное значение улучшения, полученного при рассмотрении случайных параметров. Столбец 〈max ARI〉 указывает среднее значение наилучшей точности, полученной для каждого набора данных.
https://doi.org/10.1371/journal.pone.0210236.t010
В таблице 11 мы показываем производительность алгоритмов для набора данных DB10C200F. Для всех методов было получено высокое значение p. С другой стороны, среднее повышение точности, как правило, было ниже, чем в случае набора данных DB2C200F.
Таблица 11. Многопараметрический анализ, выполненный в наборе данных DB10C200F.
Значение p представляет вероятность того, что набор классификаторов со случайной конфигурацией параметров превосходит тот же набор классификаторов со своими параметрами по умолчанию.〈 R 〉, Δ R и max R представляют собой среднее, стандартное отклонение и максимальное значение улучшения, полученного при рассмотрении случайных параметров. Столбец 〈max ARI〉 указывает среднее значение наилучшей точности, полученной для каждого набора данных.
https://doi.org/10.1371/journal.pone.0210236.t011
Выводы
Кластеризация данных — сложная задача, включающая выбор между множеством различных методов, параметров и показателей производительности, что имеет значение для многих реальных проблем [63, 103–108].Следовательно, анализ преимуществ и недостатков алгоритмов кластеризации также является сложной задачей, которой уделяется много внимания. Здесь мы подошли к этой задаче, сосредоточив внимание на комплексной методологии для создания большого разнообразия разнородных наборов данных с точно определенными свойствами, такими как расстояния между классами и корреляции между объектами. Используя пакеты на языке R, мы провели сравнение производительности девяти популярных методов кластеризации, примененных к 400 искусственным наборам данных.Были рассмотрены три ситуации: параметры по умолчанию, изменение одного параметра и случайное изменение параметров. Тем не менее следует иметь в виду, что все результаты, представленные в этой работе, относятся к конкретным конфигурациям нормально распределенных данных и алгоритмических реализаций, так что в других ситуациях можно получить другую производительность. Помимо практического руководства по применению методов кластеризации, когда исследователь не является экспертом в методах интеллектуального анализа данных, был получен ряд интересных результатов, касающихся рассмотренных методов кластеризации.
Что касается параметров по умолчанию, разница в производительности методов кластеризации не была значительной для низкоразмерных наборов данных. В частности, тест Краскела-Уоллиса на различия в производительности при рассмотрении двух характеристик привел к p-значению p = 6,48 × 10 −7 (с расстоянием хи-квадрат × 2 = 41,50). Для 10 объектов значение p равно p = 1,53 × 10 −8 ( × 2 = 52.20). Рассмотрение 50 характеристик привело к значению p p = 1,56 × 10 −6 для теста Краскела-Уоллиса ( × 2 = 41,67). Для 200 объектов полученное значение p составило p = 2,49 × 10 −6 ( × 2 = 40,58).
Спектральный метод обеспечил лучшую производительность при использовании параметров по умолчанию, со скорректированным индексом ранда (ARI) 68,16%, как указано в таблице 2. Напротив, иерархический метод дал ARI, равный 21.34%. Также интересно, что недооценка количества классов в наборе данных привела к худшей производительности, чем в ситуациях с завышенной оценкой. Это наблюдалось для всех алгоритмов и соответствует предыдущим результатам [44].
Что касается вариаций одного параметра, то для наборов данных, содержащих 2 функции, иерархический, оптический и электромагнитный методы показали значительные различия в производительности. С другой стороны, для наборов данных, содержащих 10 или более функций, большинство методов можно легко улучшить, изменив выбранные параметры.
Что касается многомерного анализа наборов данных, содержащих десять классов и два объекта, производительность алгоритмов многомерного выбора параметров была аналогична работе с параметрами по умолчанию. Это говорит о том, что алгоритмы нечувствительны к вариациям параметров для этого набора данных. Для наборов данных, содержащих два класса и десять функций, EM, hcmodel, подпространство и иерархический алгоритм показали значительный выигрыш в производительности. Алгоритм EM также привел к высокому значению p (70.8%), что указывает на то, что многие значения параметров для этого алгоритма могут обеспечить лучшие результаты, чем конфигурация по умолчанию. Для наборов данных, содержащих десять классов и десять функций, улучшение было значительно ниже почти для всех алгоритмов, за исключением иерархической кластеризации. Когда было рассмотрено большое количество объектов, например, в случае наборов данных, содержащих 200 объектов, для всех методов наблюдался значительный прирост производительности.
В таблицах 12, 13 и 14 мы приводим сводку лучших показателей точности, полученных в ходе нашего анализа.Таблицы содержат лучшую производительность, измеренную как ARI результирующих разделов, достигнутую каждым алгоритмом в трех рассмотренных ситуациях (по умолчанию, одномерная и многомерная настройка параметров). Результаты относятся к наборам данных DB2C2F, DB10C2F, DB2C10F, DB10C10F, DB2C200F и DB10C200F. Мы заметили, что для наборов данных, содержащих 2 функции, алгоритмы, как правило, показывают одинаковую производительность, особенно при увеличении количества классов. Для наборов данных, содержащих 10 или более функций, спектральный алгоритм, по-видимому, постоянно обеспечивает лучшую производительность, хотя EM, иерархические, k-средние и подпространственные алгоритмы также могут достичь аналогичной производительности с некоторой настройкой параметров.Следует отметить, что некоторые алгоритмы кластеризации, такие как optics и dbscan, нацелены на другие распределения данных, такие как удлиненные или S-образные [72, 74]. Следовательно, для данных с ненормальным распределением могут быть получены разные результаты.
Таблица 12. Сводная таблица производительности алгоритмов кластеризации в наборах данных DB2C2F и DB10C2F.
ARI def представляет собой среднюю точность, полученную при рассмотрении параметров алгоритмов по умолчанию.представляет собой среднее значение наилучшей точности, полученной при изменении одного параметра. представляет собой среднее значение наилучшей точности, полученной при случайном выборе параметров.
https://doi.org/10.1371/journal.pone.0210236.t012
Таблица 13. Сводная таблица производительности алгоритмов кластеризации в наборах данных DB2C10F и DB10C10F.
ARI def представляет собой среднюю точность, полученную при рассмотрении параметров алгоритмов по умолчанию.представляет собой среднее значение наилучшей точности, полученной при изменении одного параметра. представляет собой среднее значение наилучшей точности, полученной при случайном выборе параметров.
https://doi.org/10.1371/journal.pone.0210236.t013
Таблица 14. Сводная таблица производительности алгоритмов кластеризации в наборах данных DB2C200F и DB10C200F.
ARI def представляет собой среднюю точность, полученную при рассмотрении параметров алгоритмов по умолчанию.представляет собой среднее значение наилучшей точности, полученной при изменении одного параметра. представляет собой среднее значение наилучшей точности, полученной при случайном выборе параметров.
https://doi.org/10.1371/journal.pone.0210236.t014
В будущих расширениях этой работы можно будет сравнить другие алгоритмы. Важным аспектом, который также можно изучить, является рассмотрение других статистических распределений для моделирования данных. Кроме того, аналогичный подход может быть применен к полууправляемой классификации.
Вспомогательная информация
Файл S2. Производительность кластеризации, полученная при случайном выборе параметров.
Файл содержит рисунки, показывающие гистограммы значений ARI, полученные для идентификации кластеров соответственно наборов данных DB10C10F и DB2C10F с использованием случайного выбора параметров. Каждый график соответствует методу кластеризации, рассмотренному в основном тексте.
https://doi.org/10.1371/journal.pone.0210236.s002
(PDF)
Ссылки
- 1.Голдер С.А., Мэйси М.В. Суточное и сезонное настроение меняются в зависимости от работы, сна и продолжительности светового дня в разных культурах. Наука. 2011; 333 (6051): 1878–1881. pmid: 21960633
- 2. Мишель Дж. Б., Шен Ю. К., Эйден А. П., Верес А., Грей М.К., Пикетт Дж. П. и др. Количественный анализ культуры с использованием миллионов оцифрованных книг. Наука. 2011. 331 (6014): 176–182. pmid: 21163965
- 3. Боллен Дж., Ван де Сомпель Х., Хагберг А., Чут Р. Анализ основных компонентов 39 научных мер воздействия.PLoS ONE. 2009. 4 (6): 1–11.
- 4. Амансио Д. Р., Оливейра О. Н. Младший, Коста Л. Ф. Трехкомпонентная модель для воспроизведения топологии сетей цитирования и влияния видимости авторов на их индекс Хирша. Журнал информетрики. 2012; 6 (3): 427-434.
- 5. Дин Дж., Гемават С. MapReduce: Упрощенная обработка данных в больших кластерах. Сообщество ACM. 2008. 51 (1): 107–113.
- 6. Виана МП, Амансио Д.Р., Коста Л.Ф. В меняющихся во времени сетях сотрудничества.Журнал информетрики. 2013; 7 (2): 371–378.
- 7. Aggarwal CC, Zhai C. В: Aggarwal CC, Zhai C, редакторы. Обзор алгоритмов кластеризации текста. Бостон, Массачусетс: Springer США; 2012. с. 77–128.
- 8. Риджуэй Дж., Мэдиган Д. Последовательный метод Монте-Карло для байесовского анализа массивных наборов данных. Интеллектуальный анализ данных и обнаружение знаний. 2003. 7 (3): 301–319. pmid: 19789656
- 9. Файяд У, Пятецкий-Шапиро Г., Смит П. От интеллектуального анализа данных к обнаружению знаний в базах данных.Журнал AI. 1996; 17 (3): 37.
- 10. Беллацци Р., Зупан Б. Прогностический анализ данных в клинической медицине: текущие проблемы и рекомендации. Международный журнал медицинской информатики. 2008. 77 (2): 81–97. pmid: 17188928
- 11. Абдулла З., Хераван Т., Ахмад Н., Дерис М.М. Извлечение положительных ассоциативных правил из данных о зачислении студентов. Процедурно-социальные и поведенческие науки. 2011; 28: 107–111.
- 12. Хашей М., Биджари М. Модель искусственной нейронной сети (p, d, q) для прогнозирования временных рядов.Экспертные системы с приложениями. 2010. 37 (1): 479–489.
- 13. Иоахимс Т. Категоризация текста с машинами опорных векторов: обучение с множеством соответствующих функций. В: Европейская конференция по машинному обучению. Springer; 1998. с. 137–142.
- 14. Виттен И. Х., Фрэнк Э. Интеллектуальный анализ данных: практические инструменты и методы машинного обучения. 2-е изд. Сан-Франциско: Морган Кауфманн; 2005.
- 15. Ван И, Фан И, Бхатт П., Давацикос К. Регрессия многомерного паттерна с использованием машинного обучения: от медицинских изображений до непрерывных клинических переменных.Нейроизображение. 2010. 50 (4): 1519–1535. pmid: 20056158
- 16. Блюм А.Л., Лэнгли П. Подборка актуальных функций и примеров машинного обучения. Искусственный интеллект. 1997. 97 (1): 245–271.
- 17. Цзин Л., Нг М.К., Хуанг Дж.З. Алгоритм энтропийного взвешивания k-средних для подпространственной кластеризации разреженных данных большой размерности. IEEE Transactions по знаниям и инженерии данных. 2007. 19 (8): 1026–1041.
- 18. Сузуки Р., Шимодаира Х. Pvclust: пакет R для оценки неопределенности в иерархической кластеризации.Биоинформатика. 2006. 22 (12): 1540–1542. pmid: 16595560
- 19. Камастра Ф., Верри А. Новый метод ядра для кластеризации. IEEE Transactions по анализу шаблонов и машинному анализу. 2005. 27 (5): 801–805. pmid: 15875800
- 20. Юнг Ю.Г., Кан М.С., Хео Дж. Сравнение производительности кластеризации с использованием алгоритмов K-средних и максимизации ожиданий. Биотехнология и биотехнологическое оборудование. 2014; 28 (sup1): S44 – S48.
- 21. Киннунен Т., Сидоров И., Туононен М., Френти П.Сравнение методов кластеризации: тематическое исследование независимого от текста моделирования говорящего. Письма о распознавании образов. 2011. 32 (13): 1604–1617.
- 22. Аббас О.А. Сравнение алгоритмов кластеризации данных. Int Arab J Inf Technol. 2008. 5 (3): 320–325.
- 23. Пирим Х., Экшиоглу Б., Перкинс А.Д., Юджир Ç. Кластеризация данных экспрессии генов с высокой пропускной способностью. Компьютеры и исследования операций. 2012. 39 (12): 3046–3061.
- 24. Costa IG, Carvalho FdATd, Souto MAlCPd.Сравнительный анализ методов кластеризации данных о динамике экспрессии генов. Генетика и молекулярная биология. 2004; 27: 623-631.
- 25.
de Souto MC, Costa IG, de Araujo DS, Ludermir TB, Schliep A. Кластеризация данных экспрессии гена рака: сравнительное исследование. Биоинформатика BMC. 2008; 9 (1): 497. pmid: 1
21
- 26. Догерти Э. Р., Баррера Дж., Брун М., Ким С., Сезар Р. М., Чен Ю. и др. Вывод из кластеризации с применением микрочипов экспрессии генов.Журнал вычислительной биологии. 2002. 9 (1): 105–126. pmid: 117
- 27. Brohée S, van Helden J. Оценка алгоритмов кластеризации для сетей взаимодействия белок-белок. BMC Bioinformatics. 2006; 7 (1): 1–19.
- 28. Маулик У., Бандёпадхьяй С. Оценка производительности некоторых алгоритмов кластеризации и индексы достоверности. IEEE Transactions по анализу шаблонов и машинному анализу. 2002. 24 (12): 1650–1654.
- 29. Фрейли С., Рафтери А.Е.Сколько кластеров? Какой метод кластеризации? Ответы с помощью кластерного анализа на основе моделей. Компьютерный журнал. 1998. 41 (8): 578–588.
- 30. Халкиди М., Батистакис Ю., Вазирджаннис М. О методах проверки кластеризации. Журнал интеллектуальных информационных систем. 2001. 17 (2-3): 107–145.
- 31. Жаккар П. Нувель исследует флоральное распространение. Bulletin de la Sociète Vaudense des Sciences Naturelles. 1908; 44: 223–270.
- 32. Лоуренс Х., Араби П.Сравнение перегородок. Журнал классификации. 1985. 2 (1): 193–218.
- 33. Фаулкс Э. Б., Мэллоуз С. Л. Метод сравнения двух иерархических кластеров. Журнал Американской статистической ассоциации. 1983. 78 (383): 553–569.
- 34. Штрел А., Гош Дж., Карди К. Кластерные ансамбли — структура повторного использования знаний для объединения нескольких разделов. Журнал исследований в области машинного обучения. 2002; 3: 583–617.
- 35. Hirschberger M, Qi Y, Steuer RE.Случайное создание ковариационных матриц выбора портфеля с заданными характеристиками распределения. Европейский журнал операционных исследований. 2007. 177 (3): 1610–1625.
- 36. Амансио Д.Р., Комин С.Х., Казанова Д., Травьезо Дж., Бруно О.М., Родригес Ф.А. и др. Систематическое сравнение контролируемых классификаторов. ПлоС один. 2014; 9 (4): e94137. pmid: 24763312
- 37. Берхин П. // Коган Дж., Николай Ч., Тебулль М., ред. Обзор методов интеллектуального анализа данных кластеризации.Берлин, Гейдельберг: Springer Berlin Heidelberg; 2006. с. 25–71.
- 38. Hwang CR. Имитационный отжиг: теория и приложения. Acta Applicandae Mathematicae. 1988. 12 (1): 108–111.
- 39. Голдберг DE, Голландия JH. Генетические алгоритмы и машинное обучение. Машинное обучение. 1988. 3 (2): 95–99.
- 40. Хокинс DM. Проблема переобучения. Журнал химической информации и компьютерных наук. 2004. 44 (1): 1–12. pmid: 14741005
- 41.Джейн А.К., Мурти М.Н., Флинн П.Дж. Кластеризация данных: обзор. Опросы ACM computing. 1999. 31 (3): 264–323.
- 42. Основная команда разработчиков R. R: Язык и среда для статистических вычислений; 2006 г. Доступно по адресу: http://www.R-project.org.
- 43. Kou G, Peng Y, Wang G. Оценка алгоритмов кластеризации для анализа финансовых рисков с использованием методов MCDM. Информационные науки. 2014; 275: 1–12.
- 44. Эрман Дж., Арлитт М., Маханти А.Классификация трафика с использованием алгоритмов кластеризации. В: Материалы семинара SIGCOMM 2006 г. по данным сетей добычи полезных ископаемых. ACM; 2006. с. 281–286.
- 45. Mingoti SA, Lima JO. Сравнение нейронной сети SOM с нечеткими c-средними, K-средними и традиционными алгоритмами иерархической кластеризации. Европейский журнал операционных исследований. 2006. 174 (3): 1742–1759.
- 46. Mangiameli P, Chen SK, West D. Сравнение нейронной сети SOM и методов иерархической кластеризации.Европейский журнал операционных исследований. 1996. 93 (2): 402–417.
- 47. Парсонс Л., Хак Э., Лю Х. Оценка алгоритмов кластеризации подпространств. В: Семинар по кластеризации многомерных данных и их приложений, SIAM Int. Конф. по интеллектуальному анализу данных. Citeseer; 2004. с. 48–56.
- 48. Бердик Д., Калимлим М., Герке Дж. МАФИЯ: алгоритм максимального набора часто встречающихся элементов для транзакционных баз данных. В: Материалы 17-й Международной конференции по инженерии данных.Вашингтон, округ Колумбия, США: Компьютерное общество IEEE; 2001. с. 443–452.
- 49. Парсонс Л., Хак Э., Лю Х. Кластеризация подпространств для многомерных данных: обзор. Информационный бюллетень ACM SIGKDD Explorations. 2004. 6 (1): 90–105.
- 50. Верма Д., Мейла М. Сравнение алгоритмов спектральной кластеризации. Технический представитель Вашингтонского университета UWCSE030501. 2003; 1: 1–18.
- 51. UCI. рак груди-Висконсин ;. Доступно по адресу: https: // http: //archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/.
- 52. Ульч А. Кластеризация с помощью сом: U * c. В: Материалы 5-го семинара по самоорганизующимся картам. т. 2; 2005. с. 75–82.
- 53. Гуха С., Растоги Р., Шим К. Лечение: эффективный алгоритм кластеризации для больших баз данных. Информационные системы. 2001; 26 (1): 35–58.
- 54. Аггарвал СС, Редди СК. Кластеризация данных: алгоритмы и приложения. т. 2. 1-е изд. Чепмен и Холл / CRC; 2013.
- 55. Карипис Г., Хан Э., Кумар В.Хамелеон: иерархическая кластеризация с использованием динамического моделирования. Компьютер. 1999. 32 (8): 68–75.
- 56. Хуанг Дж., Сун Х., Кан Дж., Ци Дж., Дэн Х., Сон К. ESC: эффективный алгоритм кластеризации на основе синхронизации. Системы, основанные на знаниях. 2013; 40: 111–122.
- 57. Wu X, Kumar V, Quinlan JR, Ghosh J, Yang Q, Motoda H и др. 10 лучших алгоритмов интеллектуального анализа данных. Системы знаний и информации. 2008. 14 (1): 1–37.
- 58. Джайн А.К., Топчий А., Закон М.Х., Бухманн Дж.Пейзаж алгоритмов кластеризации. В: Распознавание образов, 2004. ICPR 2004. Труды 17-й Международной конференции по. т. 1. IEEE; 2004. с. 260–263.
- 59. Джайн АК. Кластеризация данных: 50 лет за пределами K-средних. Письма о распознавании образов. 2010. 31 (8): 651–666.
- 60. Стейнли Д. Кластеризация К-средних: полувековой синтез. Британский журнал математической и статистической психологии. 2006; 59 (1): 1–34. pmid: 16709277
- 61. Dunn JC.Нечеткий родственник процесса ISODATA и его использование для обнаружения компактных хорошо разделенных кластеров. Кибернетика. 1973; 3: 32–57.
- 62. Хуанг З. Расширения алгоритма k-средних для кластеризации больших наборов данных с категориальными значениями. Интеллектуальный анализ данных и открытие знаний. 1998. 2 (3): 283–304.
- 63. Райков Ю.П., Букувалас А, Баиг Ф, Литтл М.А. Что делать, когда кластеризация K-средних не удается: простой, но принципиальный альтернативный алгоритм. PLoS ONE. 2016; 11 (9): 1–28.
- 64. Kaufman L, Rousseeuw PJ. Поиск групп в данных: введение в кластерный анализ. Серия по вероятностной и математической статистике. 2009 ;.
- 65. Артур Д., Васильвицкий С. k-means ++: Преимущества тщательного посева. В: Материалы восемнадцатого ежегодного симпозиума ACM-SIAM по дискретным алгоритмам. Общество промышленной и прикладной математики; 2007. с. 1027–1035.
- 66. Секейра К., Заки М. ADMIT: анализ данных на основе аномалий для вторжений.В: Материалы восьмой международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных. ACM; 2002. с. 386–395.
- 67. Уильямс Г.Дж., Хуанг З. Разработка шахты знаний. В: Австралийская объединенная конференция по искусственному интеллекту. Springer; 1997. стр. 340–348.
- 68. Маккуин Дж. Некоторые методы классификации и анализа многомерных наблюдений. В: Труды Пятого симпозиума Беркли по математической статистике и вероятности, Том 1: Статистика.Беркли, Калифорния: Калифорнийский университет Press; 1967. с. 281–297.
- 69. Хартиган Дж. А., Вонг М. А.. Алгоритм AS 136: алгоритм кластеризации k-средних. Журнал Королевского статистического общества, серия C. 1979; 28 (1): 100–108.
- 70. Kaufman L, Rousseeuw PJ. Поиск групп в данных: введение в кластерный анализ. Джон Уайли и сыновья; 1990.
- 71. Хан Дж., Камбер М. Интеллектуальный анализ данных. Концепции и методы. т. 2. 2-е изд. -: Морган Кауфманн; 2006 г.
- 72. Анкерст М., Бреуниг М.М., Кригель Х.П., Сандер Дж. ОПТИКА: упорядочивающие точки для определения структуры кластеризации. SIGMOD. 1999. 28 (2): 49–60.
- 73. Анкерст М., Бреуниг М.М., Кригель Х.П., Сандер Дж. ОПТИКА: упорядочивающие точки для определения структуры кластеризации. ACM Press; 1999. стр. 49–60.
- 74. Эстер М., Кригель Х.П., Сандер Дж., Сюй Х. Алгоритм на основе плотности для обнаружения кластеров. Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом.В: Материалы Второй Международной конференции по открытию знаний и интеллектуальному анализу данных. КДД’96. AAAI Press; 1996. стр. 226–231.
- 75. Лэнс Г. Н., Уильямс В. Т.. Общая теория классификационных стратегий сортировки II. Системы кластеризации. Компьютерный журнал. 1967. 10 (3): 271–277.
- 76. Реднер Р., Уокер Х. Плотности смеси, максимальное правдоподобие и алгоритм em. SIAM Обзор. 1984; 26 (6).
- 77. Демпстер А.П., Лэрд Н.М., Рубин Д.Б.Максимальная вероятность получения неполных данных с помощью алгоритма EM. Журнал Королевского статистического общества, серия B. 1977; 39 (6).
- 78. Фрейли С., Рафтери А.Е. Кластеризация на основе моделей, дискриминантный анализ и оценка плотности. Журнал Американской статистической ассоциации. 2002. 97 (458): 611–631.
- 79. Фрейли С., Рафтери А.Е. MCLUST: Программное обеспечение для кластерного анализа на основе моделей. Журнал классификации. 1999. 16 (2): 297–306.
- 80. Фрейли С., Рафтери Э.А.Программное обеспечение для расширенной модельно-ориентированной кластеризации, оценки плотности и дискриминантного анализа: MCLUST ». Журнал классификации. 2003. 20 (2): 263–286.
- 81. Фрейли С. Алгоритмы для гауссовской иерархической кластеризации на основе моделей. Журнал СИАМ по научным вычислениям. 1998. 20 (1): 270–281.
- 82. Шварц Г. Оценка размерности модели. Летопись статистики. 1978. 6 (2): 461–464.
- 83. Насименто MC, Де Карвалью AC. Спектральные методы кластеризации графов — обзор.Европейский журнал операционных исследований. 2011. 211 (2): 221–231.
- 84. Филиппоне М., Камастра Ф., Масулли Ф., Роветта С. Обзор ядерных и спектральных методов кластеризации. Распознавание образов. 2008. 41 (1): 176–190.
- 85. Фон Люксбург У. Учебное пособие по спектральной кластеризации. Статистика и вычисления. 2007. 17 (4): 395–416.
- 86. Ng AY, Jordan MI, Weiss Y. О спектральной кластеризации: анализ и алгоритм. В: Достижения в системах обработки нейронной информации 14.MIT Press; 2001. с. 849–856.
- 87. Диллон И.С., Гуан Й., Кулис Б. Единый взгляд на k-средние ядра, спектральную кластеризацию и разрезы графа. Citeseer; 2004.
- 88. Кригель Х. П., Крегер П., Зимек А. Кластеризация подпространств. Междисциплинарные обзоры Wiley: интеллектуальный анализ данных и открытие знаний. 2012. 2 (4): 351–364.
- 89. Сим К., Гопалкришнан В., Зимек А., Конг Г. Обзор расширенной кластеризации подпространств. Интеллектуальный анализ данных и открытие знаний. 2013. 26 (2): 332–397.
- 90. Берже Л., Бувейрон С., Жирар С. HDclassif: пакет R для модельно-ориентированной кластеризации и дискриминантного анализа многомерных данных. Журнал статистического программного обеспечения. 2012; 46 (6): 1-29.
- 91. Бувейрон С., Жирар С., Шмид К. Высокомерная кластеризация данных. Вычислительная статистика и анализ данных. 2007. 52 (1): 502–519.
- 92. Лючак М. Объединение необработанных и нормализованных данных в многомерной классификации временных рядов с динамической деформацией времени.Журнал интеллектуальных и нечетких систем. 2018; 34 (1): 373–380.
- 93. Гуха С., Мейерсон А., Мишра Н., Мотвани Р., О’Каллаган Л. Кластеризация потоков данных: теория и практика. Транзакции IEEE по знаниям и инженерии данных. 2003. 15 (3): 515–528.
- 94. Silva JA, Faria ER, Barros RC, Hruschka ER, De Carvalho AC, Gama J. Кластеризация потоков данных: обзор. ACM Computing Surveys. 2013; 46 (1): 13.
- 95. Хорн Р.А., Джонсон С.Р. Матричный анализ.2-е изд. Нью-Йорк, Нью-Йорк, США: Издательство Кембриджского университета; 2012.
- 96. Лю И, Ли З, Сюн Х, Гао Х, Ву Дж. Понимание мер проверки внутренней кластеризации. В: Data Mining (ICDM), 10-я Международная конференция IEEE 2010 г. IEEE; 2010. с. 911–916.
- 97. Лей Й., Бездек Дж. К., Романо С., Винь Н. X., Чан Дж., Бейли Дж. Смещение основополагающей истинности в индексах валидности внешнего кластера. Распознавание образов. 2017; 65: 58–70.
- 98. Cover TM, Thomas JA.Элементы теории информации. т. 2. Вайли; 2012.
- 99. Strehl A, Ghosh J. Кластерные ансамбли — структура повторного использования знаний для объединения нескольких разделов. Журнал исследований машинного обучения. 2002; 3: 583–617.
- 100. Брун М., Сима С., Хуа Дж., Лоуи Дж., Кэрролл Б., Су Е. и др. Модельная оценка мер проверки кластеризации. Распознавание образов. 2007. 40 (3): 807–824.
- 101. Арбелаитц О., Гуррутсага И., Мугерза Дж., Перес Дж. М., Перона И.Обширное сравнительное исследование показателей кластерной валидности. Распознавание образов. 2013. 46 (1): 243–256.
- 102. McKight PE, Тест Наджаба Дж. Крускала-Уоллиса. Энциклопедия психологии Корсини. 2010 ;.
- 103. Арруда Г.Ф., Коста Л.Ф., Родригес Ф.А. Комплексный сетевой подход для кластеризации данных. Physica A: Статистическая механика и ее приложения. 2012; 391 (23): 6174-6183.
- 104. Наени Л.М., Крейг Х., Берретта Р., Москато П. Новая методология кластеризации, основанная на оптимизации модульности для выявления сходства авторства в пьесах эпохи Шекспира.PLOS ONE. 2016; 11 (8): 1–27.
- 105. Амансио ДР. Распознавание авторства посредством анализа колебаний топологии сети и перемежаемости слов. Журнал статистической механики: теория и эксперимент. 2015; 2015 (3): P03005.
- 106. Гарсия К. Боклюст: Алгоритм стабильности начальной кластеризации для обнаружения сообществом. PLOS ONE. 2016; 11 (6): 1–15.
- 107. Colavizza G, Franceschet M. Кластеризация историй цитирования в Physical Review.Журнал информетрики. 2016; 10 (4): 1037-1051.
- 108. Бенайм М. Стохастическая модель нейронной сети для обучения без учителя. Письма еврофизики. 1992; 19 (3): 241.
Сравнение трех онлайн-программ в университете
Нари Ким
Докторант
Технологии учебных систем
Университет Индианы в Блумингтоне
800 Н. Юнион-стрит, APT # 401
Блумингтон, Индиана 47408
812-345-4605
Электронная почта: narkim @ indiana.edu
Мэтью Дж. Смит
Лейтенант-командир
Береговая охрана США
USCGC Mobile Bay (WTGB 103)
1543 Пенсильвания-стрит
Стерджен-Бэй, WI 54235
920-743-2646
Электронная почта: Matthew.j.smith@uscg .mil
Kyungeun Maeng
младший консультант
Отдел обучения и развития
Korea Productivity Center
122-1, Juk-Sun Dong, Jong-no Gu, Seoul, South Korea
82-02-724-1134
E-mail: kemaeng @ kpc.or.kr
Абстрактные
Целью данного исследования было выяснить, отражены ли принципы оценивания в онлайн-образовании в оценочной деятельности, используемой разработчиками и администраторами реальных дистанционных онлайн-курсов.Были проанализированы три программы дистанционного обучения в режиме онлайн, реализуемые в крупном университете Среднего Запада; Школа непрерывного обучения — дистанционная программа бакалавриата, Школа бизнеса — дистанционная программа MBA и Школа образования — дистанционная программа магистратуры. Результаты исследования показали, что оценочная деятельность дистанционных онлайн-курсов не строго следует принципам, предложенным в литературе.
Введение
Несмотря на недавний интерес к дистанционному онлайн-обучению в системе высшего образования, существует скудная литература о том, как оценивать успеваемость учащихся в среде дистанционного онлайн-образования.Поскольку оценка является важной линзой, сквозь которую рассматривается образование (Bransford, Brown, & Cocking, 2000), и движущей силой успеваемости учащихся, авторы считают ее важным компонентом любой программы дистанционного обучения онлайн, требующей дальнейшего изучения. Авторы изучили литературу, чтобы определить общие принципы оценки успеваемости учащихся в контексте дистанционного онлайн-образования, и исследовали, отражены ли эти принципы в оценочных мероприятиях, используемых разработчиками и администраторами реальных дистанционных онлайн-курсов.В своих исследованиях они руководствовались двумя ключевыми вопросами:
- Применяется ли теория оценки обучения студентов в дистанционном онлайн-образовании на практике в системе высшего образования?
- Отличаются ли методы, используемые для оценки обучения студентов в программах дистанционного обучения, в зависимости от предмета / дисциплины курса?
Пытаясь ответить на эти вопросы, авторы проанализировали схемы оценки выбранных курсов из трех программ дистанционного обучения в режиме онлайн в большом университете Среднего Запада.Классифицируя свои схемы оценивания и количественно оценивая степень использования различных методов, авторы смогли сделать предварительные выводы о состоянии оценивания на онлайн-курсах крупного университета Среднего Запада. Авторы надеются, что их работа послужит пилотным исследованием для стимулирования дальнейших исследований в этой области.
Определения оценки
Прежде чем исследовать, какие стратегии и методы оценивания подходят для дистанционного онлайн-образования и в какой степени эти методы применяются в университете, авторы сначала установили определения понятий.Поскольку оценка, оценка, области знаний, онлайн и дистанционное образование — это термины, значения которых могут варьироваться в зависимости от точки зрения, определения или рамки, выбранные авторами для их описания, служили границами, чтобы сделать их анализ более управляемым, а их обсуждение более точным. .
Во-первых, в этом анализе авторы решили взглянуть на онлайн-курсы через призму четырехуровневой модели Киркпатрика. В частности, авторов интересовал уровень 2: обучение, который Киркпатрик определил как «степень, в которой участники меняют отношение, улучшают знания и / или повышают навыки в результате посещения программы» (Kirkpatrick, 1998).Несмотря на то, что акцент в модели Киркпатрика был сделан на оценке программ обучения, авторы считали его модель наиболее полезным способом сузить очень широкую идею оценки дистанционных онлайн-курсов.
Авторы решили еще больше сузить область охвата до оценивания в программах дистанционного обучения онлайн (основа для оценки программы Уровня 2) по двум причинам. Во-первых, авторы сочли анализ оценок Уровня 3 (Поведение) и 4 (Результаты) в программах дистанционного обучения онлайн как слишком амбициозную цель, учитывая их временные и ресурсные ограничения, не говоря уже об общем отсутствии оценки на этих уровнях, что стало очевидным для них в их первоначальном обзоре онлайн-программ.Во-вторых, авторы считают анализ стратегий и методов оценивания в среде дистанционного обучения онлайн как наиболее полезный аспект темы и наиболее актуальный для учебных стратегий дистанционного образования в целом. В-третьих, уровень 2 лучше знаком с заинтересованными сторонами — преподавателями, студентами, администраторами и т. Д.
Области знаний оценки
Еще одна важная концепция, которая повлияла на исследования авторов по этой теме, — это области знаний.Силс и Глазго (1990) обсудили три общепринятых области знаний в качестве психологической основы учебного дизайна — аффективную, когнитивную и психомоторную. В дополнение к этим областям Ромишовски (1981) определил недостающую область — социальные / межличностные / интерактивные навыки, которые, возможно, необходимо развивать и, следовательно, (логически) оценивать в зависимости от результатов курса или программы. Авторы считают, что ни одно исследование дистанционных онлайн-курсов не будет завершенным, если не посмотреть, как эти области учитываются в их схемах оценивания; поэтому термин «области знаний» означает четыре области, перечисленные выше.
Определение дистанционного обучения в Интернете
Наконец, определение объема проведенного авторами анализа потребовало принятия решения об определении понятия «дистанционное онлайн-образование». Что касается «дистанционного образования», авторы решили использовать определение Кигана (1990, стр. 44) в качестве рабочей модели, которая включает «квазипостоянное разделение учителя и ученика на протяжении всего учебного процесса», «влияние образовательного процесса». организация, использование технических средств массовой информации »,« обеспечение двусторонней связи »и« почти постоянное отсутствие учебной группы на протяжении всего учебного процесса… так что людей обычно обучают индивидуально, а не группами ».
Авторы решили определить« онлайн »как использование Интернета (World Wide Web) как« технических средств массовой информации », используемых для обеспечения« двух- способ общения », требуемого определением Кигана. Авторы решили, что степень, в которой курс позволяет преподавателю использовать Интернет для достижения организованной совокупности результатов обучения для студентов, работающих удаленно (отдельно от преподавателя, а также друг от друга), была степень, в которой это был дистанционный онлайн-курс обучения.Таким образом, курсы могут рассматриваться в соответствии с этим определением как «курсы дистанционного обучения в режиме онлайн», несмотря на то, что они могут иметь небольшой компонент «лицом к лицу» или «жилой».
Принципы оценивания в дистанционном онлайн-образовании
Новые технологии сделали возможными частые и разнообразные оценки в среде дистанционного онлайн-обучения по сравнению с традиционной учебной средой (Meyen, Aust, Bui, & Isaacson, 2002). Тем не менее, авторы должны помнить, что самое важное при оценивании в новой среде онлайн-обучения — это по-прежнему сосредотачиваться на достижениях учащихся с точки зрения учебных целей и задач.Следовательно, даже несмотря на то, что технологии могут эффективно и действенно облегчить процесс оценивания, авторы должны выбирать подходящие возможности оценки только тогда, когда оценки необходимы во время обучения.
За последние несколько десятилетий многие исследователи были убеждены, что оценка успеваемости учащихся в дистанционной онлайн-среде должна быть неотъемлемой частью обучения, быть непрерывной и обеспечивать максимальную обратную связь (Meyen et al., 2002). Основываясь на этих общих взглядах на онлайн-оценку, авторы обсудят несколько принципов оценивания в следующих параграфах.
Прежде всего, Государственный университет Пенсильвании (1998 г.) разработал набор принципов, которыми можно руководствоваться при оценивании в дистанционном онлайн-образовании. Эти принципы оценивания могут быть исходным руководством для разработки оценки достижений учащегося «в целом». Основываясь на своем предположении, что оценка и измерение должны служить ценным целям как для преподавателей, так и для студентов, в этих принципах подчеркивается важность интеграции оценки с обучением следующим образом (стр.7):
- Инструменты и мероприятия оценки должны согласовываться с целями обучения и навыками, необходимыми учащемуся на протяжении всей программы или курса дистанционного обучения.
- Стратегии оценки и управления должны быть неотъемлемой частью процесса обучения, позволяя учащимся оценивать свой прогресс, определять области анализа и восстанавливать немедленные цели обучения или урока.
- Стратегии оценивания и измерения должны учитывать особые потребности, характеристики и ситуации дистанционного учащегося.
- Дистанционным учащимся должны быть предоставлены широкие возможности и доступные методы для предоставления обратной связи относительно учебного плана программы дистанционного обучения.
С другой стороны, в плане разработки онлайн-оценивания Кибби (2003) объяснил, что онлайн-обучение и оценивание следует рассматривать не только в рамках подхода, ориентированного на учащегося, но также и в рамках подхода центра учителя (например, системы управления). . Она подчеркнула, что оценка через Интернет может помочь учащимся взять на себя ответственность за свое обучение, поскольку оценка может обеспечить интеграцию обучения и оценки, а также немедленную и эффективную обратную связь с учащимися.Таким образом, сетевые системы оценивания могут иметь больший потенциал, чем бумажные системы оценивания, с точки зрения доступа и гибкости как для учащихся, так и для учителей в эффективном и действенном управлении. Для разработки веб-оценки она предложила принять следующие ключевые решения (Kibby, 2003):
- Какие перспективы обучения будут оцениваться: когнитивные (приобретение знаний), поведенческие (развитие навыков) или гуманистические (ценности и отношения)?
- Кто будет проводить оценку: студент, его сверстники или преподаватель?
- Будут ли стратегии оценки познавать опыт сами по себе?
- Должна ли оценка быть формативной (обеспечение обратной связи во время обучения) или итоговой (измерение обучения в конце процесса)?
- Приводятся ли оценки эффективности в соответствии со стандартами коллег (ссылка на норму) или установленными критериями (ссылка на критерий)?
- Как оценка может обеспечить баланс между структурой и свободой?
- Будет ли оценка достоверной, связанной с реальными жизненными ситуациями?
- Будет ли оценка интегрирована, проверяя ряд знаний и навыков?
- Как можно гарантировать надежность и достоверность оценки?
Особенности оценивания в дистанционном онлайн-образовании
Основываясь на нескольких образовательных философиях, таких как бихевиоризм и конструктивизм, существуют различные особенности оценивания в дистанционном онлайн-образовании, которые подчеркиваются с разных точек зрения.Однако в этом исследовании авторы не делали различий между этими различными философиями образования, чтобы искать особенности оценивания в онлайн-среде. Вместо того, чтобы разделять эти образовательные подходы на противоположные стороны, авторы попытались выяснить наиболее важные особенности оценивания, которые можно было бы использовать в качестве подходящих стратегий оценивания в среде дистанционного онлайн-обучения. Поэтому, основываясь на традиционных стратегиях оценивания, предлагаемых для очной учебной среды, в следующих разделах авторы обсудят некоторые особенности оценивания, которые имеют решающее значение для успеха онлайн-оценивания.
Текущая оценка: формирующая оценкаСогласно Concord Consortium (2002), использование одного «традиционного теста с высокими ставками» для измерения успеваемости учащихся может быть эффективным и действенным в контролируемом классе. Однако онлайн-оценка должна быть «непрерывным, непрерывным процессом». Например, Консорциум Concord рекомендовал преподавателям находить свидетельства достижений в ежедневных вкладах отдельных участников в их группу онлайн-обучения, например в онлайн-обсуждениях.Кроме того, преподаватели должны попытаться выяснить «уникальную деятельность или подход каждого студента к решению учебных задач» через свои идеи, размещенные на доске обсуждений.
С другой стороны, когда авторы рассматривают текущее оценивание как измерение процесса обучения, этот тип оценивания можно назвать формирующим оцениванием. Согласно Брансфорду, Вай и Бейтману (2002), формативное оценивание служит как студентам, так и преподавателям во многих конкретных аспектах. Например, «учащиеся могут использовать обратную связь с формирующими оценками, чтобы помочь им узнать, что они еще не усвоили и что им нужно изучать дальше» (стр.174). Благодаря такой формирующей оценке у студентов появляется больше возможностей рассмотреть свою учебную задачу с другой точки зрения на основе отзывов преподавателя. Кроме того, с информацией, полученной в результате формирующего оценивания, инструкторы могут изменить свое обучение, сделав его более эффективным и действенным, и нацелить его на студентов, нуждающихся в дополнительной помощи (Bransford et al., 2002).
Таким образом, текущая или формирующая оценка может быть неотъемлемой частью обучения в среде дистанционного обучения онлайн, которая позволяет легко отслеживать индивидуальную учебную деятельность по сравнению с традиционной классной средой.Однако для того, чтобы максимизировать преимущества этих текущих оценок при обучении через Интернет, система онлайн-управления должна иметь возможность эффективно и наглядно предоставлять преподавателям накопленные данные об учебной деятельности и оценках учащихся.
Отзыв в оценкеЕсли оценка должна быть неотъемлемой частью обучения, как объяснено выше, обратная связь должна играть центральную роль в процессе оценки (Meyen et al., 2002). По сравнению с традиционной учебной средой, среда онлайн-обучения сделала эту центральную роль обратной связи достижимой с точки зрения времени и доступа к информации.В ходе непрерывной оценки сетевой среды Керка и Вонакотт (2000) объяснили, что важность обратной связи с преподаванием может напрямую влиять на то, что студенты изучают и насколько эффективно они будут это делать. Особенно простое использование электронных коммуникаций может поддержать центральную роль обратной связи в оценке через Интернет. Действительно, правильная и немедленная обратная связь может преобразовать опыт оценивания в учебный опыт для учащихся (Meyen et al., 2002). Коллис, Де Боар и Слотман подчеркнули важность поддержки со стороны инструктора для облегчения обратной связи в среде онлайн-обучения.Кроме того, они упомянули «практические последствия обратной связи в контексте временных затрат, ясности ожиданий для студентов и эффективности управления общим процессом представления и обратной связи (Meyen et al., 2002, p. 191)». В качестве примера обратной связи Collis et al. представил «личную обратную связь преподавателя по индивидуальному заданию, модель-ответ, предоставленную преподавателем, оценку коллег, предоставленную студентом (ами), и автоматическую прямую обратную связь, предоставленную компьютером (Meyen et al., 2002, с. 191). »
При обсуждении эффективности обратной связи в дистанционном онлайн-обучении Meyen et al. (2002) признали, что в очном курсе (традиционная среда обучения) они не могли дать стратегическую обратную связь и обеспечить тот же уровень обратной связи, который они могли бы в ситуации онлайн-курса, даже несмотря на то, что синхронная обратная связь была возможна в классе. . Такие результаты показывают, что электронная обратная связь в дистанционном онлайн-курсе может быть более эффективной, чем у традиционного курса.
СамооценкаСамооценка должна быть основным компонентом дистанционного обучения онлайн (Robles & Braathen, 2002). Некоторые преподаватели могут захотеть оценивать обучение студентов только сами. Однако Роблес и др. считал, что для учащихся будет очень важно участвовать в оценке собственного обучения, потому что учащиеся могут измерять свой собственный учебный процесс и достижения. Они также подчеркнули, что студенты могут иметь возможность определять, «достигли ли они требуемых учебных целей, и что в противном случае они могут повторить курсовую работу» самостоятельно для достижения своих собственных целей (стр.45). Например, предварительные онлайн-тесты могут быть рассмотрены для этой самооценки, потому что учащиеся смогут получить немедленную обратную связь после прохождения предварительных тестов, чтобы определить свой существующий уровень знаний (Robles & Braathen, 2002). С помощью предварительных тестов студенты могут узнать свой текущий уровень знаний перед тем, как начать онлайн-курсы, выбрать подходящие уровни курсов и снова пройти тест, чтобы измерить свои достижения после завершения курсов. Эти предварительные тесты также могут позволить учащимся чувствовать себя более комфортно с самим материалом или его учебными целями.
Оценка команды и коллегиальная оценкаИз-за замечательного эффекта совместного обучения в классе «многие онлайн-курсы также направлены на развитие у студентов способности работать в команде и включают в себя задачи групповой оценки, такие как презентации, проекты, тематические исследования, отчеты, дебаты и т. Д. на «(Freeman & McKenzie, 2002, стр. 552). Гохейл (2003) объясняет, что совместное обучение может быть хорошим «методом обучения, при котором учащиеся с разным уровнем успеваемости работают вместе в небольших группах для достижения общей цели.Студенты несут ответственность за обучение друг друга, а также за свое собственное. Таким образом, успех одного ученика помогает другим стать успешными. «Однако, согласно Freeman and McKenzie (2002), хотя многие ученики чувствуют ценность обучения в командах и развития навыков командной работы, они не считают, что их командная оценка является приемлемой». справедливый метод оценки, если члены команды получают одинаковое вознаграждение за неравный вклад (стр. 552). «Таким образом, повышение справедливости командного оценивания имеет важное значение для повышения эффективности обучения учащихся при выполнении командных задач.Сводные данные при оценке со стороны коллег могут побудить учащихся конфиденциально оценивать свой собственный вклад и вклад своих сверстников в выполнение командных задач и поддержку команды. Кроме того, они считали, что преимущества улучшения обучения студентов с помощью задач командной работы и экономии времени за счет автоматизации процесса расчета самостоятельных и других корректировок оценок могут быть особенно привлекательными для большого числа учащихся, обучающихся на курсах университетского уровня.
Подлинная оценкаГрант (1990) настаивал на том, что оценка должна быть достоверной, если авторы захотят напрямую измерить успеваемость учащегося по достойным интеллектуальным задачам, а не по типу косвенных тестовых заданий, на которые традиционные оценки полагаются как на эффективные и упрощенные заменители.Обсуждая особенности аутентичного оценивания, он пояснил, что аутентичное оценивание может предоставить учащимся полный спектр задач. Эти задания могут потребовать от учащихся отражения приоритетов и проблем, представленных в хороших учебных мероприятиях (например, сотрудничество с другими в дискуссии), в то время как обычные тесты будут относительно ограничены вопросами с бумагой и карандашом или вопросами с одним ответом. Кроме того, он предположил, что аутентичная оценка может обеспечить валидность и надежность за счет стандартизации соответствующих критериев для выставления оценок студенческим продуктам, в отличие от традиционного тестирования, которое стандартизирует объективные элементы и один правильный ответ для каждого элемента.Однако, помимо этих технических соображений, он предположил, что этот новый подход к оценке будет основан на предпосылке, что оценка должна в первую очередь поддерживать потребности учащихся. Грант считал, что лучшая оценка должна научить студентов и учителей одинаково важному виду работы.
Таким образом, электронные портфолио были предложены как лучший тип аутентичной оценки в среде дистанционного обучения онлайн (Meyen et al., 2002). Для вышеупомянутых функций, описанных как аутентичная оценка, электронные портфолио могут развиваться как инструмент управления как для преподавателей, так и для студентов с появлением дистанционного обучения онлайн.Эти электронные портфолио могут отслеживать студенческие процессы и облегчать не только формативное оценивание, но и итоговое оценивание. В частности, с помощью этих электронных портфолио формирующая оценка может служить для выявления сильных и слабых сторон учебного процесса учащегося с надлежащей обратной связью.
Методы оценивания в дистанционном онлайн-обучении
Во многих статьях предлагаются методики онлайн-оценки. Однако, согласно Rovai (2000), общие принципы оценки в онлайн-среде не отличаются; изменяется только способ применения принципов.В свете этого Rovai (2000) предложил некоторые методы оценки для онлайн-курсов. Среди них он особо выделил контролируемое тестирование и онлайн-обсуждения. Существует три вида контролируемого тестирования для дистанционных курсов: отложенный телефонный разговор, онлайн-чат или электронная почта; контролируемое тестирование в децентрализованных местах и централизованных резиденциях на территории кампуса. Он представил, что контролируемое тестирование способствует безопасности личности и академической честности — двум сложным вопросам дистанционного образования. Тестирование под наблюдением рекомендуется для итоговой оценки с высокими ставками.
Роваи (2000) также рекомендовал онлайн-обсуждение как хороший метод оценки. Способность онлайн-дискуссии продвигать текстовое общение может способствовать накоплению знаний. Это также будет способствовать размышлениям посредством асинхронного онлайн-взаимодействия лучше, чем в традиционных классах. Преподаватели могут использовать эти интерактивные взаимодействия как для итоговой, так и для формирующей оценки. Для достоверной оценки успеваемости Роваи (2000) предложил проекты и тематические исследования, которые уникальны и актуальны для отдельного учащегося, с дополнительным преимуществом, заключающимся в том, что они могут помочь решить проблемы, связанные с безопасностью личности и академической честностью.
Роблес и Браатен (2002) заявили, что методы оценки, используемые в традиционных классах, могут быть изменены, чтобы отразить природу и педагогику дистанционных настроек. Предлагая несколько онлайн-методов оценки, они утверждали, что можно использовать различные инструменты оценки, чтобы определить, достиг ли студент заранее установленных учебных целей. Предлагаемые в статье методы оценки: самопроверка, задания, электронное портфолио, онлайн-обсуждение, асинхронная многопоточная дискуссионная группа, одноминутная работа, синхронный чат и содержание вопросов по электронной почте.
Мейен и его коллеги (2002) сказали, что варианты оценивания электронного обучения мало отличаются от тех, которые обычно используются при очном обучении. Они предложили несколько методов оценки онлайн-курса: обзор литературы, совместные проекты, экзамены, отчеты студентов в режиме реального времени, журнальные записи и электронное портфолио. Они были реализованы в онлайн-курсе, который преподавал Мейен в 1997 году. Он включил промежуточный, заключительный экзамен, упражнение по обзору литературы, совместный проект и около 30 заданий.Среди этих методов Meyen et al. (2002) сделали упор на электронное портфолио. Они заявили, что метод электронного портфолио может оценивать успеваемость учащихся как формативно, так и суммативно. Они также считают, что оценка портфолио предоставляет более точные средства измерения академических и профессиональных навыков. «Благодаря использованию технологий электронное портфолио в формате гипермедиа может стать системой управления личной / профессиональной информацией, которая вносит значительный вклад в педагогику электронного обучения в высшем образовании, помимо профессионального развития, и в качестве инструмента для учителей K-12.»(Мейен и др., 2002, стр. 194)
Предпочтение электронного портфолио можно увидеть в статье Девальда, Шольц-Крейна, Бута и Левина (2000). Они утверждали, что оценка электронного портфолио хорошо работает как для документов и развивать метакогнитивные навыки. Согласно статье, по мере того, как студенты все больше и больше работают в электронном виде, электронные портфолио становятся все более распространенными, особенно в среде дистанционного обучения. «В конце курса портфолио служит представлением того, что не только прогресс студента в освоении содержания курса, но также и растущее осознание студентом своих собственных навыков.Наконец, портфолио побуждают студентов развивать метакогнитивные навыки и позволяют инструктору отслеживать развитие этих навыков (Dewald et al., 2000, p. 41) ».
Методология
Чтобы ответить на вопросы исследования, авторы проанализировали три различные программы дистанционного обучения, предоставляемые в большом университете Среднего Запада; Школа непрерывного обучения — дистанционная программа бакалавриата, Школа бизнеса — дистанционная программа MBA и Школа образования — дистанционная программа магистратуры.Эти три программы являются репрезентативными дистанционными программами крупного университета Среднего Запада. Курсы бакалавриата Школы непрерывного образования, выпускные курсы Школы образования и курсы MBA для профессионалов представляют собой курсы, которые обычно предоставляются в высших учебных заведениях. Этот университет — один из крупных университетов, который может представлять другие высшие учебные заведения Среднего Запада с аналогичными условиями. Ниже приводится описание характеристик каждой программы.
Описания программ
Программа бакалавриата школы непрерывного обученияШкола непрерывного образования, основанная в 1975 году, является одним из крупнейших провайдеров дистанционного образования в США. Школа непрерывного обучения раньше предлагала заочные программы дистанционного обучения, но многие из заочных курсов были преобразованы в онлайн-курсы вместе с развитием технологий. Школа предлагает аттестат об окончании средней школы, две степени бакалавра по общеобразовательным дисциплинам (обе доступны полностью онлайн), одну степень бакалавра по образованию для взрослых (доступна онлайн с одним обязательным выходным на кампусе), более 200 университетских курсов и более 100 старших классов. курсы и возможности повышения квалификации и индивидуального обучения.Среди них авторы исследовали 16 онлайн-курсов бакалавриата.
Темы варьируются от бухгалтерского учета до оценки искусства. Все курсы Школы непрерывного обучения предназначены для самостоятельного изучения, поэтому существует только взаимодействие между преподавателем и студентом, а не между студентами. В онлайн-курсе студенты получают уроки, задания и оценки в Интернете. Они общаются с инструктором по электронной почте и отправляют задания через веб-браузер.Некоторые из курсов включают интерактивные мероприятия и виртуальные экскурсии, в которых студенты участвуют через Интернет.
Онлайн-программа MBA Школы бизнесаОнлайн-программа MBA в Школе бизнеса предназначена для того, чтобы позволить профессионалам продолжать работать полный рабочий день и выполнять семейные обязанности, одновременно получая степень MBA онлайн. Это двухлетняя программа с системой 12-недельных кварталов. Для этого требуется однонедельный «очный» курс каждый год, но остальные курсы завершаются онлайн (асинхронно с некоторыми синхронными компонентами) с использованием следующих инструментов: дискуссионные форумы, онлайн-тестирование, потоковая передача аудио / видео и симуляции / тематическое обучение.Курсы преподают штатные преподаватели Школы бизнеса. Выпускникам присваивается степень магистра делового администрирования. Авторы исследовали 14 курсов, по которым они могли получить информацию.
Школа дистанционного обучения по программам магистратурыПрограмма дистанционного образования Школы образования предлагает студентам и преподавателям полностью аккредитованные курсовые работы, проводимые через Интернет, и двустороннее интерактивное видео. Темы этой программы дистанционного обучения этой школы образования широко варьируются в начальных и средних учебных программах, включая учебные технологии, языковое образование и курсы педагогической психологии.Эта программа предлагает кредиты на уровне выпускников для соответствия требованиям сертификации и повторной сертификации в школьных округах по всей стране и по всему миру, чтобы стать частью магистерской программы в университете Среднего Запада или в другом учреждении. Эта программа также предлагает несколько курсов для студентов, которые только начинают работать над сертификацией. В частности, эта дистанционная программа подтверждает наличие магистерских программ по учебным технологиям и языковому образованию. Поэтому среди магистерских программ авторы выбрали 7 курсов по учебной технологии и 3 курса по языковому образованию, чтобы проанализировать оценку своей программы.
Инструменты и обоснование
Собрав информацию о курсе, авторы классифицировали различные методы оценки, чтобы выяснить, какие методы оценки используются на самом деле. Во-первых, авторы разделили их на формирующую оценку и итоговую оценку. Формирующие оценки относятся к методам оценки процесса обучения, а не результатов обучения. Скорее, итоговые оценки — это оценка результатов обучения. Например, викторины, которые даются в конце раздела и оценивают их понимание каждого из них, считаются формирующими, в то время как промежуточные или заключительные экзамены для оценки результатов их обучения в конце семестра или в конце более крупного единицы считаются суммативными.Промежуточные части текущего проекта или документа — еще один пример формирующей оценки, в то время как окончательный результат проекта — метод итоговой оценки.
Как уже говорилось в обзоре литературы, обратная связь чрезвычайно важна. Согласно Брансфорду (2001), обратная связь наиболее ценна, когда студенты имеют возможность использовать ее для изменения своего мышления во время работы над модулем или проектом. С этой точки зрения формирующие оценки, которые даются в процессе обучения, также важны в дистанционной обстановке.Посредством формирующего оценивания преподаватели могут получить представление о том, насколько студенты достигли своих целей, и могут пересмотреть свои инструкции в соответствии с результатами формирующего оценивания.
Во-вторых, авторы разделили их на групповую оценку и индивидуальную оценку. Командная оценка означает, что оценка равномерно выставляется группе людей, которые работали вместе. Индивидуальная оценка заключается в том, что человек получает свою собственную оценку за индивидуальную работу. Авторы сделали эту категорию из-за важности совместной работы.Одним из недостатков системы дистанционного обучения является сложность взаимодействия или совместного обучения. Благодаря взаимодействию между учащимися или процессу совместного обучения они могут учиться друг у друга и давать обратную связь, а также приобретать навыки межличностного общения. Командная оценка также важна для достоверности оценки. В бизнес-среде большинство проектов выполняется в команде. Следовательно, даже в дистанционной среде совместное обучение должно проводиться ради аутентичности, и авторы хотели знать, как это делается на реальных курсах.
Затем авторы решили классифицировать схемы оценивания выбранных курсов по различным использованным методам оценивания:
- Работа / эссе: Академические письменные работы, кроме письменного «экзамена». Это потребует большей подготовки, повторения и т. Д., Чем простой ответ на прямой вопрос (как на экзамене).
- Экзамен / викторина / набор задач: целенаправленное краткосрочное мероприятие, используемое для измерения конкретного обучения. Включает письменные ответы на вопросы, расчеты, краткий ответ, множественный выбор, заполнение бланка и т. Д.
- Обсуждение / чат: любое мероприятие, на котором учащийся может обсуждать или обсуждать темы, связанные с классом. Также включает «участие» или степень, в которой учащиеся делятся своими мнениями или идеями по темам, связанным с классом.
- Проект / Моделирование / Практический пример: Действия, которые более «аутентичны» или ориентированы на выполнение конкретных задач, чем экзамен или чисто академическая работа. Может быть производство мультимедиа, участие в симуляции, письменный анализ и т. Д.
- Размышление: упражнение, призванное побудить учащихся связать материал со своим опытом, или журналы о том, как обучение в классе конкретно относится к ним (извлеченные уроки и т. Д.)
- Портфолио (коллекция индивидуальной продукции): интегрированная коллекция студенческих работ, предназначенная для использования в целом. Синтез успеваемости учащегося за определенный период времени против события.
- Оценки со стороны сверстников: оценка, проводимая сверстниками, обычно для измерения успеваемости учащегося в групповых занятиях.
Таблица 1. Категории оценивания, используемые для анализа онлайн-курсов
| Тип оценки | |
Формирующая оценка |
|
Суммарная оценка |
|
Команда vs.Индивидуальная оценка | |
Индивидуальная оценка |
|
Оценка команды |
|
Инструмент / метод оценки | |
Бумага / эссе |
|
Экзамен / викторина / |
|
Обсуждение / чат |
|
Проект / Моделирование / Практический пример |
|
Отражение |
|
Портфель |
|
Экспертные оценки |
|
Процедура
Изучив дистанционные онлайн-курсы в крупном университете Среднего Запада в целом, авторы выбрали удобную выборку курсов из каждой из трех дистанционных программ, обсуждавшихся ранее.Авторы получили разрешение на доступ к программам курса или веб-сайтам от администраторов курса или инструкторов каждой программы. Для анализа они использовали только информацию, содержащуюся в документах, которые им удалось получить. Авторы определились с нашими тремя типами категорий оценки (формирующая / итоговая, командная / индивидуальная и методы оценки) на основе информации в документах и нашем обзоре литературы и использовали эти категории для классификации методов, используемых в схемах оценки выбранных нами дистанционные онлайн-курсы.Затем они проанализировали данные количественно (процентное соотношение категорий оценивания) и качественно (описание курсов), чтобы определить ответы на вопросы исследования.
Результаты
Данные о схемах оценивания, используемых на дистанционных онлайн-курсах в крупном университете Среднего Запада, сведены в Таблицу 2. Более пристальный взгляд на данные в таблице 2 проливает свет на вопрос, отражены ли рекомендации экспертов в схемах оценивания дистанционных онлайн-курсов в крупном университете Среднего Запада.В следующих разделах авторы обсудят степень, в которой каждый основной принцип или аспект эффективного оценивания на дистанционных онлайн-курсах применяется на практике.
Таблица 2. Соотношение категорий оценки среднего онлайн-курса в трех программах дистанционного обучения (см. Приложение A: Список курсов)
СКС | ГП | СОБ | Среднее значение | ||
Количество курсов | 16 | 10 | 14 | 13.33 | |
Тип оценки | Формирующая оценка | 47,69% | 78,00% | 40,71% | 55,47% |
Суммарная оценка | 52,31% | 22,00% | 59,29% | 44,53% | |
Итого | 100.00% | 100,00% | 100,00% | 100,00% | |
Командная и индивидуальная оценка | Индивидуальная оценка | 100,00% | 78,80% | 76,79% | 85,2% |
Оценка команды | 0.00% | 21.20% | 23,21% | 14,8% | |
Итого | 100,00% | 100,00% | 100,00% | 100,00% | |
Инструмент / метод оценки | Бумага / эссе | 40,25% | 54.20% | 13,21% | 35,89% |
Экзамен / викторина / | 58,19% | 4,00% | 47,50% | 36,56% | |
Обсуждение / чат | 0,00% | 14,50% | 10,36% | 8.29% | |
Проект / моделирование / пример из практики | 1,56% | 10,25% | 18,21% | 10,00% | |
Отражение | 0,00% | 8,35% | 0,00% | 2,78% | |
Портфель (сбор индивидуальной продукции) | 0.00% | 6.50% | 0,00% | 2,17% | |
Экспертные оценки | 0,00% | 2,20% | 7,14% | 3,11% | |
Итого | 100,00% | 100,00% | 100,00% | 100.00% | |
SCS: Школа непрерывного обучения
SOE: Школа образования
SOB: Школа бизнеса
Формирующее оценивание и отзывы студентов
Данные показывают, что в той или иной степени текущая или формирующая оценка является важной особенностью каждой из трех программ. В целом формирующая оценка успеваемости учащихся составляет 55% от общей оценки. Аналогичным образом, формирующее оценивание является особенностью всех курсов Школы непрерывного обучения (SCS) и Школы образования (SOE), а также половины курсов Школы бизнеса (SOB), проанализированных авторами.
На курсах SCS формативное оценивание обычно принимает форму письменных заданий в конце каждого урока, которые включают множественный выбор, краткий ответ и вопросы для сочинения. Правильные ответы на эти задания составляют обратную связь, которую получают учащиеся. На курсах SOE формативная оценка фактически составляет гораздо большую долю (78%) от общей оценки, чем итоговая. Это достигается в отделе учебных технологий (ИТ) за счет использования асинхронного обсуждения и постоянной документации групповых проектов.Обратная связь, полученная по этим промежуточным результатам, применяется к следующей фазе проекта в формирующей манере. В отделении языкового образования (LE) формирующая оценка принимает форму более простых инструментов, таких как короткие отдельные работы, которые не являются частью более крупного (группового) проекта. Как и в случае с ИТ-программой, отзывы на эти работы используются для повышения успеваемости учащихся. Наконец, на курсах SOB формирующая оценка / обратная связь со студентами проводятся с помощью набора задач, краткого анализа случаев, промежуточных заявок на проекты и обсуждения.Интересно, что разница в использовании формирующей и суммативной оценки в программе SOB была больше; четыре курса полностью основывались на итоговых показателях, а три других полностью полагались на формирующие меры для оценки успеваемости студентов по курсу.
Аутентичная оценка
Как видно из Таблицы 2, подавляющее большинство оценивания во всех трех онлайн-программах остается относительно «традиционным» по своей природе — это работы, эссе, экзамены, викторины и наборы задач.Эти меры, которые ничем не отличаются от своих аналогов в очных курсах, составляют 72% от общей оценки студентов.
Программа SCS больше всего зависит от этих традиционных мер, на 98%. Фактически, в программе фактически используются промежуточные и заключительные экзамены «на месте» в качестве основного метода оценки. Каждая программа SOE и SOB опирается на традиционные меры примерно для 60% оценки студентов, но с разным акцентом. Программа SOE в значительной степени отдает предпочтение оценкам на бумаге / эссе, в то время как SOB отдает предпочтение экзаменам, викторинам и комплексам задач.
В следующих разделах более подробно будут описаны способы, которыми эти программы используют более «аутентичные» методы (онлайн-обсуждение, проект / моделирование / тематическое исследование, размышления / портфолио, совместные проекты, а также коллегиальные или самооценки) для измерения успеваемости учащихся.
Обсуждение в сети
Онлайн-обсуждение / чат является важной особенностью программ SOE (15%) и SOB (10%), но полностью отсутствует на курсах SCS из-за их полностью индивидуального подхода.Обсуждение используется в программах SOE для двух разных целей. В ИТ-отделе обсуждение используется для взаимодействия между членами группы в процессе выполнения командных заданий. В отделе LE обсуждение используется больше для передачи их индивидуальных идей относительно отдельных заданий, над которыми они работают. В программе SOB обсуждение используется для одной или обеих целей в зависимости от курса.
Проекты / Моделирование / Примеры использования
Возможно, наиболее достоверная форма оценки, проектов, моделирования и тематических исследований составляет крайне незначительную (1.5%) доля курсов SCS и более значительная доля оценки студентов в программах SOE (10%) и SOB (18%). В SCS единственное требование к проекту, по иронии судьбы, является одним из самых «аутентичных», поскольку от студентов требуется сделать аудиозапись для курса коммуникаций. В ИТ-отделе госпредприятий курсы в значительной степени опираются на настоящие учебные проекты, которые обычно выполняются в рамках команды и часто для реальных клиентов. В отделе LE проекты менее ориентированы на продукт и выполняются индивидуально.В SOB студенты выполняют широкий спектр аналитических проектов, бизнес-моделирования и анализа бизнес-кейсов как в индивидуальном, так и в командном формате.
Reflection / Электронное портфолио
Еще одна пара «аутентичных» методов оценки, упражнения на рефлексию и электронный портфель, являются исключительной прерогативой госпредприятий с показателями 8% и 6,5% соответственно. Упражнения на размышление используются в четырех курсах ИТ-отдела и трех курсах кафедры LE. ИТ-отдел использует электронное портфолио для всесторонней оценки производственных способностей, которых достигли студенты онлайн-курсов.
Команда, коллеги и самооценка
Командная оценка совместной деятельности, хотя и полностью отсутствует в программе SCS, является важным фактором в программах SOE (21%) и SOB (23%), которые представлены в половине курсов каждой программы. Эта командная оценка принимает форму «групповых» оценок, выставляемых за проекты, выполненные в команде на этих курсах, будь то учебные проекты в области ИТ или бизнес-моделирование / анализ кейсов в бизнес-курсах. Совместная оценка (взаимная оценка) используется вместе с этими групповыми оценками только в трех курсах ИТ и одном курсе SOB.Интересно, однако, что курс SOB (электронная коммерция), который использует экспертную оценку, использует ее как единственный метод оценки в курсе.
Хотя это отличный инструмент, самооценка не занимает заметного места ни в одной из трех программ, но в небольшой степени предлагается в каждой из них. Лучше всего он представлен в программе SCS и представляет собой раздел для самопроверки (без оценки) на каждом уроке. В SOE (ИТ-отдел) самооценка предлагается в виде загружаемых тестов.Функция неклассифицированной викторины предлагается только в одном курсе SOB.
Оценка различных областей знаний
Из обзора программы каждого курса авторы не смогли определить оценку какой-либо области знаний, кроме когнитивной. Ни один из результатов курса не описан в терминах желаемых аффективных изменений или улучшения психомоторных или межличностных навыков, а схемы оценки, по-видимому, не предназначены для измерения этих типов результатов.
Вполне вероятно, что можно было бы рассматривать ряд курсов SOE (IT) и SOB как вероятных кандидатов для развития и оценки навыков межличностного общения из-за значительного объема встроенной в них групповой работы.Однако в той степени, в которой это может происходить, это не является четко сформулированным результатом этих программ и не является объектом их схем оценки. Поэтому авторы не считают, что какие-либо области знаний, к которым обращается какая-либо из этих программ, помимо когнитивной области.
Обсуждение
Следуют ли эти три программы руководству литературы по дистанционному обучению онлайн?
В целом авторы приходят к выводу, что курсы, проанализированные в рамках этих трех программ, не следуют рекомендациям из литературы относительно оценивания на курсах дистанционного обучения онлайн.Причина такого вывода заключается в том, что они демонстрируют относительно низкое общее использование более аутентичных методов оценки, предложенных Meyen et al. (2002) и Кибби (2003) — совместные проекты / групповые оценки, проект / моделирование / тематическое исследование, обсуждение / чат, размышления, портфолио и коллегиальная оценка. Если бы в курсах были представлены более достоверные оценки, подтверждающие потребности учащихся, у учащихся было бы больше шансов отразить приоритеты и проблемы во всем диапазоне их задач (Grant, 1990), поделиться своей информацией и построить новые знания (Rovai, 2000). ).Тем не менее, эти курсы в значительной степени по-прежнему основываются на тех же типах оценивания, а именно на бумаге / эссе или экзамене / викторине / наборе задач, которые встречаются в традиционных очных курсах, упомянутых Kibby (2003) и Concord Consortium (2002). . Курсы Школы непрерывного обучения являются наиболее яркими примерами этого, в то время как курсы Школы образования и Школы бизнеса в большей степени отражают предложения литературы из-за более широкого использования аутентичных методов оценки успеваемости учащихся.Заметным исключением из этой тенденции является область формирующего оценивания, поскольку каждая из трех программ использует формирующее оценивание как важную особенность своих общих схем оценивания, как рекомендовано в литературе (Meyen et al. 2002; Пенсильванский государственный университет, 1998 г.) . Таким образом, студенты могут иметь больше возможностей для отражения своих задач с различных точек зрения на основе практических отзывов преподавателя посредством формирующих оценок (Bransford et al., 2002).
Есть ли различия между программами в инструментах оценки?
Авторы заметили несколько различий между программами, которые авторы могут отнести к природе контекста и тематике курсов.Во-первых, курсы SCS ясно продемонстрировали использование традиционных методов, таких как документы и тесты, при полном исключении более достоверных оценок. Авторы объясняют отсутствие достоверных оценок тем фактом, что курсы SCS намеренно разработаны в контексте «самообучения» (в курсах может участвовать один студент), для которого совместная деятельность была бы невозможной или неуместной. Конечно, это не объясняет отсутствие других достоверных оценок; однако тот факт, что наследие онлайн-курсов SCS лежит в заочном формате, вполне может.
Курсы SOE, изученные авторами, показывают чрезвычайно высокий уровень формирующей оценки, предложенный Мейеном и его коллегами (2002). Что еще более важно, большая часть этой формирующей оценки проводилась в рамках совместных проектов «проектной группы» в ИТ-отделе, что, согласно литературным источникам, является весьма достоверным и рекомендуемым методом оценки успеваемости студентов. Обратной стороной медали является тот факт, что на курсах отдела языкового образования видное место занимали отдельные статьи / сочинения, что резко контрастировало с более аутентичными мерами ИТ-отдела.
Наконец, как и следовало ожидать от программы, ориентированной на практикующих профессионалов в бизнес-контексте, программа SOB в большей степени полагается на совместную работу и проекты / моделирование / тематические исследования (Grant, 1990; Rovai, 2000), чем две другие. Такой вывод неудивителен, учитывая клиентуру, для обслуживания которой предназначена программа; что удивительно, так это то, что эта достоверная оценка по-прежнему составляет лишь такой небольшой процент оценки в курсе. Таким образом, в программу SOB было бы важно включить больше задач и оценок для совместной работы, включая проекты и тематические исследования для содействия совместному обучению, которое может передаваться в широком диапазоне ситуаций, а не заучивание фактической информации и материалов содержания, которые легко забываются (Беннетт , Dunne, & Carre, 1999; Tsui, 2000).
Заключение и рекомендации для будущего исследования
Этот анализ трех программ в большом университете Среднего Запада показал, что схемы оценивания, используемые в онлайн-курсах дистанционного обучения, не строго следуют принципам, предложенным в литературе. Однако авторов воодушевила степень использования формирующих и аутентичных методов оценки. Авторы обнаружили, что характер каждой программы (ее история, цель и характеристики учащихся) оказал значительное влияние на используемые методы оценки.
Это исследование также подняло интересные вопросы относительно схем оценивания, принятых разработчиками дистанционных онлайн-курсов. Чтобы сделать более существенные выводы и составить более точную картину состояния оценивания онлайн-курса, авторы рекомендуют включить в последующее исследование следующие меры:
- Более тщательный и тщательный анализ схем оценивания, действующих на всех дистанционных онлайн-курсах в университете. Такая процедура позволила бы получить более сбалансированное представление об оцениваемых здесь программах, а также об университете в целом, чем ограниченная выборка авторов для удобства.
- Более глубокий анализ путем изучения причин, по которым разработчики курса предложили схему оценивания. Скорее всего, это будет включать данные интервью / опроса преподавателей и сотрудников, занимающихся дистанционным обучением.
- Оценка эффективности схем оценивания дистанционных онлайн-курсов и сравнение с результатами, достигнутыми студентами, проживающими в эквиваленте этих курсов. Это позволит лучше судить о лучших принципах и методах достижения успеха в данном контексте.
Благодаря этим улучшениям в этом исследовании исследователи смогут сделать более твердые выводы относительно эффективности различных принципов и методов оценки в контексте дистанционной онлайн-оценки, а также определить обоснованность рекомендаций, которые авторы нашли в литературе.
Список литературы
Беннетт Н., Данн Э. и Карре К. (1999). Модели предоставления основных и общих навыков в высшем образовании. Высшее образование, 37 , 71-93.
Брансфорд, Дж. Д., Браун А. Л., Кокинг Р. Р. (2000). Как люди учатся, Вашингтон, округ Колумбия: National Academy Press,
Брансфорд, Дж. Д., Вай, Н., и Бейтман, Х. (2002). Создание высококачественной среды обучения: рекомендации по исследованию того, как люди учатся. В П. А. Грэхем и Н. Г. Стейси (ред.), Экономика знаний и послесреднее образование: отчет семинара . Вашингтон, округ Колумбия: Национальная академия прессы.
Девальд, Н., Шольц-Крейн, А., Бут, А., и Левин, К. (2000). Информационная грамотность на расстоянии: вопросы учебного дизайна. Журнал академического библиотечного дела, 26 (1) . 33-44.
Freeman, M., & Mckenzie, J. (2002) SPARK, конфиденциальный веб-шаблон для самостоятельной и коллегиальной оценки совместной работы студентов: преимущества оценивания по разным предметам. Британский журнал образовательных технологий, 33, 551-569.
Гохале., А. А. (1995) Совместное обучение улучшает критическое мышление. Журнал технологического образования, 7 (1) . Получено 15 апреля 2003 г. с сайта http://scholar.lib.vt.edu/ejournals/JTE/jte-v7n1/gokhale.jte-v7n1.html
.Киган Д. (1990). Основы дистанционного образования, 2-е издание . Лондон: Рутледж.
Керка, М., Вонакотт, Дж. (2003) Сосредоточьтесь на оценке. ПОО в школах. Получено 1 апреля 2003 г. с сайта http://online.curriculum.edu.au/the_cms/tools/new-display.asp?seq=5928
.Кибби, М. (2003) Онлайн-оценка студентов.Университет Нью-Касл. Получено 3 марта 2002 г. с сайта http://www.newcastle.edu.au/discipline/sociol-anthrop/staff/kibbymarj/online/assess.html
.Киркпатрик, Д. Л. (1998). Оценка программ обучения . Сан-Франциско: Берретт-Келер.
Мейен, E.L., Aust, R.J., Bui, Y.N., & Isaacson, R. (2002). Оценка и мониторинг успеваемости студентов в среде подготовки персонала электронного обучения. Педагогическое и специальное образование, 25 (2). 187–198.
Государственный университет Пенсильвании (2002 г.). Новый набор руководящих принципов и практик для разработки и развития дистанционного образования. Государственный университет Пенсильвании. Получено 3 марта 2002 г. с сайта http://www.outreach.psu.edu/DE/IDE/
.Роблес М. и Браатен С. (2002). Методы онлайн-оценки. Delta Pi Epsilon Journal, 44 (1 ). 39-49.
Romiszowski, A.J. (1981). Устранение пробелов в существующих подходах к учебному дизайну.В Проектирование учебных систем: принятие решений при планировании курса и разработке учебных программ. Лондон: Коган Пейдж.
Роваи, А. П. (2000). Онлайн и традиционные оценки: в чем разница? Интернет и высшее образование, 3. 141-151.
Сильс, Б. Б. и Глазго, З. (1990). Психологические основы учебного дизайна. В Упражнения по учебному дизайну. Колумбус, Огайо: Меррилл.
Цуй, Л. (2000). Влияние культуры кампуса на критическое мышление студентов. Обзор высшего образования, 23 (4), 421-441.
Concord Consortium (2002). Модель электронного обучения для онлайн-курсов. Консорциум Конкорд. Получено 3 марта 2002 г., http://www.concord.org/courses/cc_e-learning_model.pdf
Wiggins, G. (1990). Случай для достоверной оценки. ЭРИК Дайджест. Получено 27 февраля 2003 г. с сайта http://ericae.net/db/edo/ED328611.htm
.Оценка очевидных потерь из-за погрешности счетчика — сравнительный подход
- Mthokozisi Ncube
- Акпофуре Тайгбену
Ключевые слова: очевидные потери воды, измерение воды, ошибки измерения, управление потерями воды, вода, не приносящая доход (NRW)
Абстрактные
Эмпирический метод определения очевидных потерь воды с использованием оценки моделей потребления и лабораторных испытаний счетчиков воды сравнивается с альтернативными методами сравнительного выставления счетов и анализа изменений счетчиков для одного из крупнейших предприятий водоснабжения в Южной Африке.Используя эмпирический метод, очевидные потери оцениваются в среднем в 12% от заявленного объема с диапазоном от 9,4% до 14,6%, который зависит от соотношений размеров счетчиков. Это совпадает с оценками 8% -10% для предприятия с прямой подачей воды хорошего качества, но с большим возрастом (> 10 лет) и низкой точностью, которые в настоящее время предлагаются в некоторых исследованиях и используются в промышленности. Оценка метода сравнительного анализа биллинга составляет 14% и зависит от того, как данные обрабатываются и анализируются.Метод смены счетчика дал оценку 4,7% только для части данных. Оба результата альтернативных методов соответствуют предыдущим исследованиям, при этом сравнительный анализ выставления счетов работает лучше, но требует дальнейшего уточнения для повышения точности и повторяемости. Эмпирический метод остается золотым стандартом при оценке очевидных потерь воды, но, несомненно, очень трудоемок, дорог и недоступен для бюджета многих коммунальных предприятий. Поэтому разработка и проверка альтернативных методологий имеют большие перспективы, но они в значительной степени зависят от исчерпывающей информации о счетчиках и достоверных наборов данных для выставления счетов, которые редко доступны в большинстве коммунальных предприятий в Африке.
Ключевые слова: кажущиеся потери воды, учет воды, ошибки измерения, управление потерями воды, вода без доходов (NRW)
Авторские права на статьи, опубликованные в этом журнале, сохраняются за Комиссией по исследованию водных ресурсов.
методов сравнительной оценки | Bizfluent
В мире бизнеса сравнительная оценка помогает лицам, принимающим решения, выбрать наиболее жизнеспособный вариант из набора возможностей.Руководители бизнеса должны выбрать капитальные проекты и инвестиции, кандидатов на работу и маркетинговые стратегии. Методы сравнительного анализа противопоставляют преимущества и недостатки каждого возможного выбора. Эти методы могут ранжировать варианты с точки зрения ожидаемой или фактической производительности. Процесс принятия решения может включать набор заранее определенных критериев, которые служат основой для сравнения.
Плюсы и минусы
Простой метод сравнительного анализа — это список плюсов и минусов. Лицо, принимающее решение, перечисляет ряд преимуществ и недостатков для каждого доступного варианта.Например, когда соискатель получает два отдельных предложения о работе в разных компаниях, он может перечислить плюсы, такие как зарплата, льготы и потенциальные возможности продвижения по службе. В списке «за» и «против» лицо, принимающее решение, обычно назначает уровень важности каждому преимуществу и недостатку. Основание для выбора зависит от того, какой вариант содержит наибольшее количество высоко оцененных преимуществ.
Числа
Числа или количественные результаты могут повлиять на процесс сравнения и выбора.Это типично, когда лицо, принимающее решение, должно выбирать между двумя или более капитальными вложениями. Руководители бизнеса изучают прогнозируемую доходность и обычно выбирают проект с наибольшим значением. Люди могут использовать прогнозируемые затраты для сравнения отпуска на Гавайях и во Флориде. Если первоочередной задачей является высокая стоимость и соблюдение заранее определенного бюджета, выигрывает выбор с более низкой стоимостью.
Перспективы
Иногда сравнительная оценка включает использование субъективных проблем, включая точки зрения, идеи, личные симпатии и антипатии.Хотя большинство менеджеров по найму этого не признают, они обычно выбирают кандидатов на работу на основе субъективных реакций на личности, внешность и мнения о профессиональном опыте. Потребители могут предпочесть одну автомобильную марку другой из-за имиджа, создаваемого их рекламными кампаниями. Предыдущий опыт работы с определенным брендом может сформировать в сознании потребителя представление о более высоком качестве, что делает его более предпочтительным по сравнению с другими вариантами.
Функции
В сравнительных оценках используются сходства и различия между функциями для сопоставления нескольких вариантов.Ярким примером этого являются продукты-заменители. Сотовые телефоны двух разных марок могут содержать набор схожих возможностей, таких как время автономной работы и программное обеспечение для просмотра веб-страниц.